
ConvNets Match Vision Transformers at Scale
Published:
论文题目:ConvNets Match Vision Transformers at Scale
发表会议:截至2023年10月27日暂无,论文版本为 arxiv-v1
第一作者:Samuel L Smith (Google DeepMind)
Question
在相同的 computational budgets (计算资源)下,Vision Transformers(ViT) 是否会比 ConvNet 好
Experiments
本文主要使用 NFNet 架构(CNN) 和原始 ViT 架构进行比较,验证它们各自在不同的 computational budgets 下的图像分类性能的差别。 首先,本文在 JFT-4B 数据集上使用不同的 epoch busgets (从 $0.25$ 到 $8$) 预训练了一系列的 NFNet 模型 (epoch busgets 简单理解就是模型训练的 epoch 数,epoch 数越多,这表示 computational budgets 越多)。 然后绘制模型在 130k 图像上的 validation loss 和 computational budgets 的图像(其中computational budgets 坐标轴是对数坐标)。如下图(Figure 2):
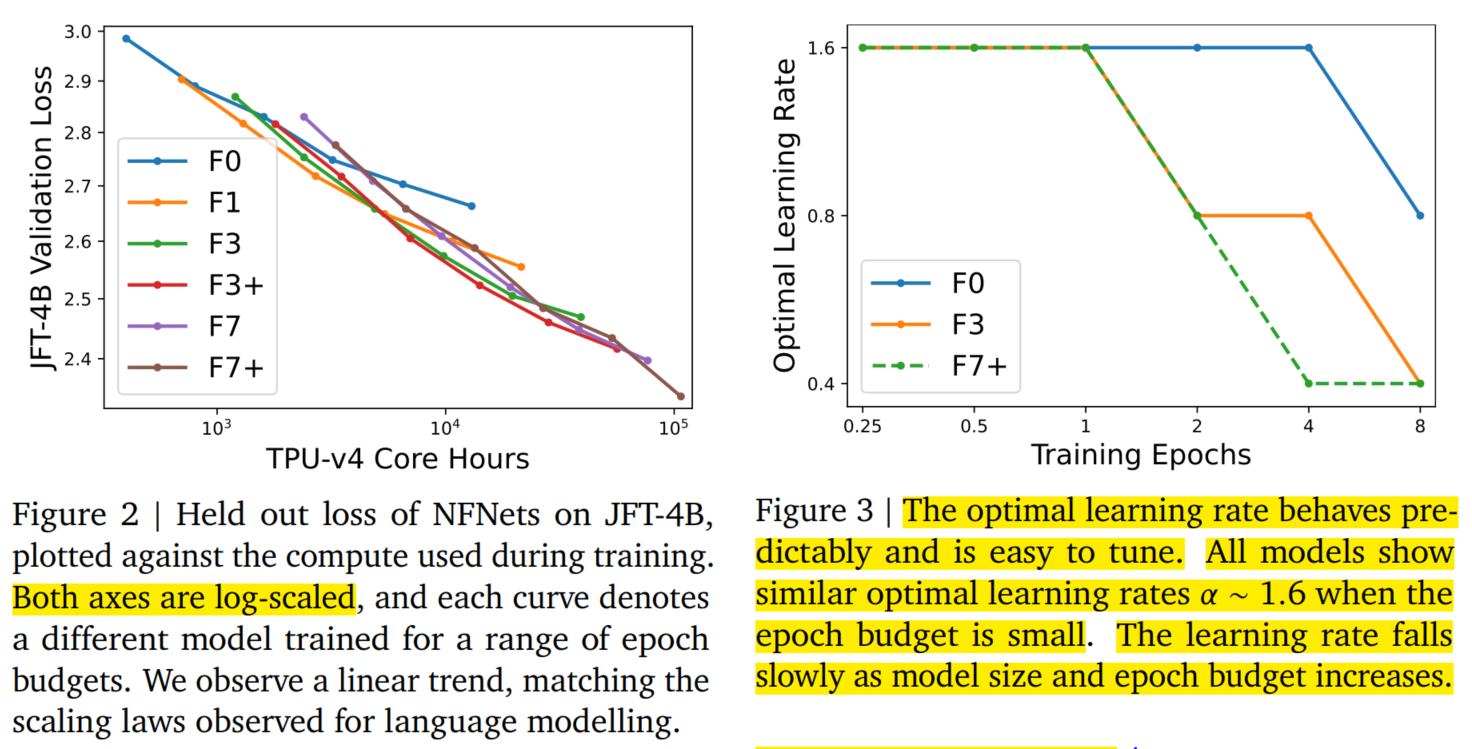
可以看到 validation loss 和预训练的 computational budgets 之间存在明显的线性趋势,与 log-log scaling law (对数标度规律)一致。 这与之前使用 transformer 进行 language modelling 时观察到的 log-log scaling law 相匹配。 同时,最优模型大小和最优 epoch budgets (实现最低验证损失)都随着 compute budgets 的增加而增加。 本文发现一个可靠的经验法则是以相同的速率扩展模型大小和训练次数,而且,当总体 compute budgets $>5k$ TPU-v4 core hours,最优 epoch budgets $>1$。
其次,本文绘制了最优学习率和 epoch budgets 之间的关系(如上图(Figure 3))。 可以看到,对于小 epoch budgets,NFNet 系列中的所有模型都显示出类似的最佳学习率 $\alpha \approx 1.6$。 然而,最优学习率随着 epoch budgets 的增加而下降,并且对于大模型,最优学习率下降得更快。 在实践中,通过假设最佳学习率随着模型大小和 epoch budgets 的增加而缓慢但单调地下降,可以在 $2$ 次试验中有效地调整学习率。
接着,本文将预训练好的 NFNets 在 ImageNet 上进行微调,并绘制了 Top-1 的错误率和 NFNets 在预训练时的 computer budgets 的关系(如下图(Figure 1))。 可以看到,随着 computer budgets 的增加,ImageNet Top-1 精度不断提高。 具体而言,本文最大的预训练模型,NFNet-F7+ 在预训练了 $8$ 个 epoch 后,实现了 $90.3\%$ 的 ImageNet Top-1 精度, 同时需要大约 $110k$ TPU-v4 core hours 进行预训练,$1.6k$ TPU-v4 core hours 进行微调。 此外,如果在微调期间额外引入重复扩增 (repeated augmentation),则可以达到 $90.4\%$ 的 Top-1 准确率。 相比之下,在没有额外数据(即没有预训练)的情况下,NFNet 在 ImageNet 上报告的最佳 Top-1 精度为 $86.8\%$ (NFNet-F5 + repeated augmentation)。 这表明 大规模的预训练对 NFNet 的性能提升是有效的。同时,相似的 computer budgets 的 NFNet 和 ViT 达到的 Top-1 准确率相似。 例如 Vit-g/14 在 JFT-3B 数据集上预训练后在 ImageNet 上的 Top-1 准确率为 $90.2\%$, 其预训练使用的 computer budgets 为 $210k$ TPU-v3 core hours (换算过来是 $120k$ TPU-v4 core hours)。 ViT-G/14 在 JFT-3B 数据集上预训练后在 ImageNet 上的 Top-1 准确率为 $90.45\%$, 其预训练使用的 computer budgets 为 $550k$ TPU-v3 core hours (换算过来是 $280k$ TPU-v4 core hours)。 SoViT-400m/14 在 JFT-3B 数据集上预训练后在 ImageNet 上的 Top-1 准确率为 $90.3\%$, 其预训练使用的 computer budgets 为 $230k$ TPU-v3 core hours (换算过来是 $130k$ TPU-v4 core hours)。
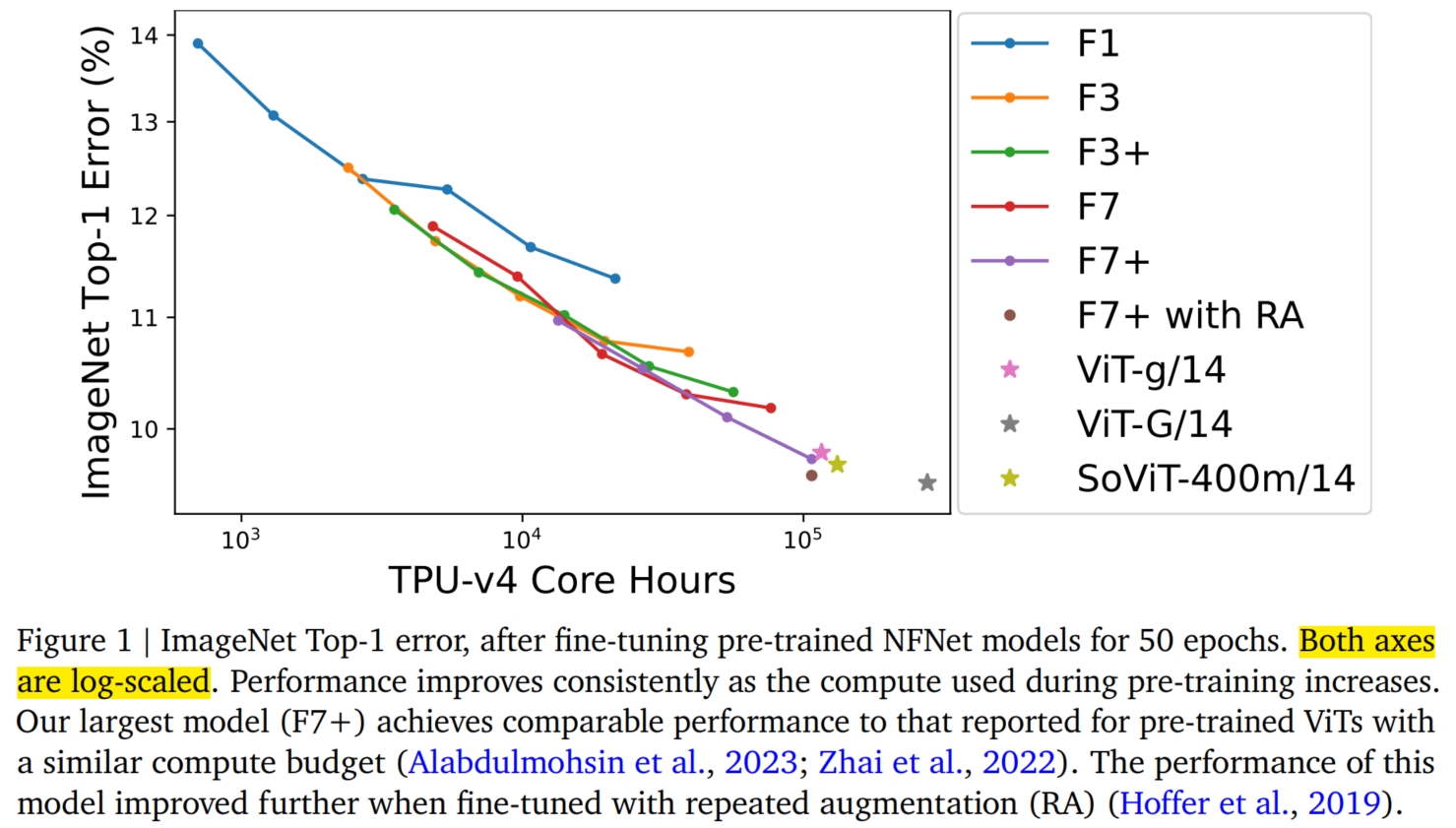
最后,本文也发现了一些有趣的性质:在 JFT-4B 上实现最低 validation loss 的预训练 checkpoints, 在微调后并不总是在 ImageNet 上实现最高的 Top-1 精度。 特别地,本文发现,在固定的预训练 computer budgets 下,微调机制始终倾向于略大的模型 + 略小的 epoch budgets 的组合。 直观地说,更大的模型具有更大的潜力,因此能够更好地适应新任务。此外,在某些情况下,稍大的学习率(在预训练期间)在微调后也取得了更好的性能。