
GLIP
Published:
论文题目:Grounded Language-Image Pre-training
发表会议:The IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR 2022)
第一作者:Liunian Harold Li (University of California at Los Angeles (UCLA))
Question
如何使得目标检测模型学习到更细粒度的,language-aware 的图像理解(即 object-level 的视觉表征),同时能做到 open-vocabulary(即不局限于给定的数据类型)
Method
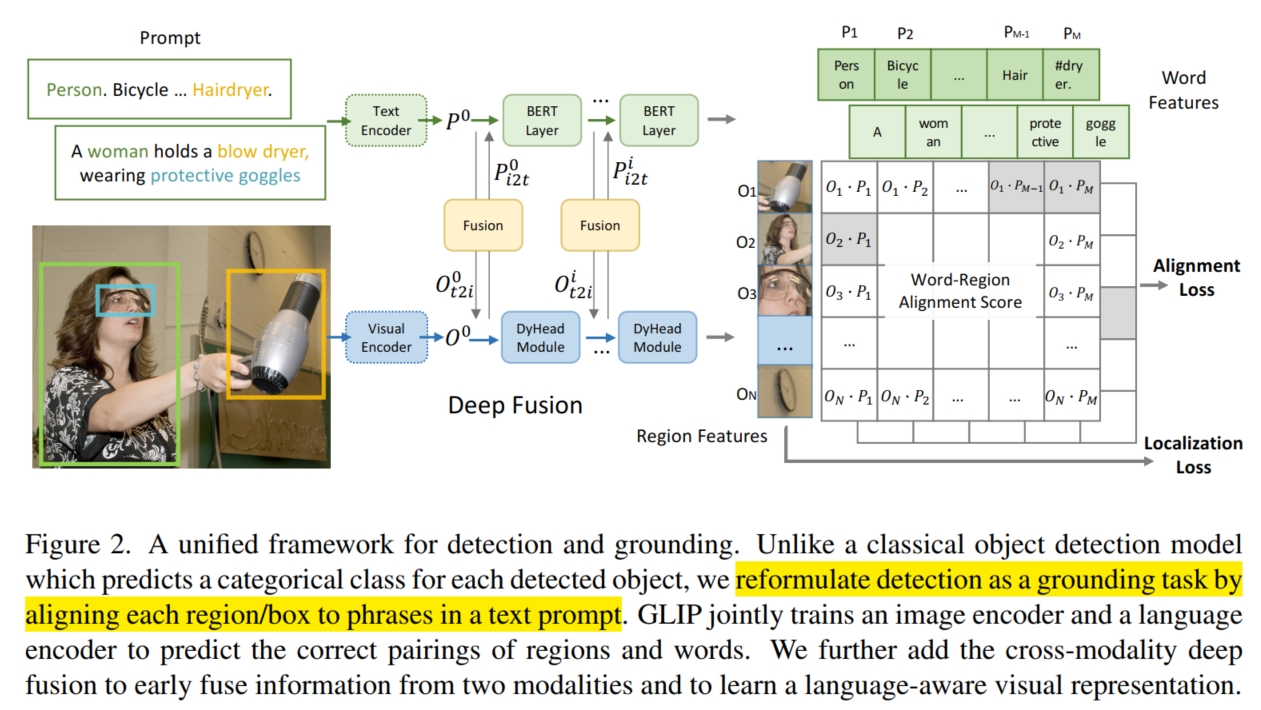
主流的目标检测模型包括一阶段和两阶段的方法。例如,两阶段的方法首先使用 RPN 网络生成大量的 anchor (predicted box), 然后对每个 anchor 学习分类器(box classifier)和定位器(box regressor)。 这就存在 3 个问题:1) 使用该架构的目标检测方法只能检测出事先给定的类别,而无法做到 open-vocabulary 的目标检测; 2) 目前而言,所有目标检测模型的类别数太少,一般不超过 2000 类,无法使得模型推广到更大的范围进行使用; 3) 这种仅仅将类别 index 作为最终分类(在训练时是将一个个类别标号为 0,1,...然后使用 Cross-entropy损失进行学习的,并没有使用/学习到语义信息)的学习方法, 不能很好地让模型学习到 language-aware 的图像表征。
为此,本文对目标检测模型进行了改进。首先是针对问题 1,借鉴于 CLIP 在分类上的 open-vocabulary 的思路(使用双塔结构计算相似度进行分类), GLIP 也使用了双塔结构并计算相似度进行目标检测。具体而言,如图,GLIP 分别使用了 Text Encoder $Enc_L$ 和 Image Encoder $Enc_I$ 对类别和图像进行编码。 在 Text-Encoder 部分,GLIP 通过一定的构造方式将类别转化为句子 $Prompt$ (例如,将每个类别按顺序进行排列并使用 . 进行分隔,就形成了句子), 然后将 $Prompt$ 送入 Text-Encoder $Enc_L$ 进行编码得到特征 $P \in R^{M \times d}$,其中 $M$ 表示 $Prompt$ 中的单词数。 在 Image-Encoder 部分,GLIP 首先通过一定的方式获得大量的 box/region (例如可以使用预训练好的 RPN), 然后将其全部送入 Image-Encoder $Enc_I$ 进行编码得到特征 $O \in R^{N \times d}$,其中 $N$ 表示 box 的个数。
对于分类,GLIP 使用点乘计算它们之间的相似度:$S_{ground} = OP^T \in R^{N \times M}$。 最后再使用 cross-entropy/focal loss 计算损失:$L_{cls} = loss(S_{ground}, T), T \in \{0,1\}^{N \times c}$, 其中 $c$ 表示类别数,$T$ 可以通过多对一匹配或者二部匈牙利算法获得。 可以看到 $S_{ground} \in R^{N \times M}$ 与 $T \in \{0,1\}^{N \times c}$ 并不匹配,通常而言 $M > c$ (因为句子中包括了很多其他的词和符号,如 .,此外一个类别还可能存在多个词等)。 所以需要将 $T$ 进行扩展。分类一般使用 focal loss 或 cross-entropy loss。 对于 focal loss,将每个类别中的所有词都规定为该类别的 positive match,并把其他额外的词都视为 negative match;对于 cross-entropy loss, 将所有没被算法(多对一匹配或者二部匈牙利算法)匹配到类别的,即 no positive match,统一将它们匹配给 $[NoObj]$ token (这是加在句子末尾表示句子结束的词),最终获得 $T'$ 送入到 $L_{cls}$ 计算损失。
而对于定位,GLIP和主流的目标检测方法一致,都是将每个 box 特征 $O_i$ 进行 ROIPool/ROIAlign, 然后送入下游网络(CNN+Linear layer)对 box 的位置偏差 $(\Delta x, \Delta y, \Delta w, \Delta h)$ 进行预测:$D_{predict} = Linear(CNN(ROIPool(O))) \in R^{N \times 4}$。 最后使用 $L_1/L_2$ loss 计算损失:$L_{loc} = \sum_{i=1}^{N}{||D_{predict}^i - D_{ground}^i||_2^2}$, 其中 $D_{ground} \in R^{N \times 4}$,表示每个 box 的真实偏差,对于没有匹配到类别的 box,其真实偏差全为 $0$。
针对问题 2,本文找到了一种非常简单好用的思路:将其他不同的任务和目标检测统一起来,使得它们之间的数据集可以共用。 具体而言,本文将 phrase grounding 和 object detection 统一到一起(统一成 phrase grounding),这样就可以使用 phrase grounding 和 objection detection 两个任务的数据集一起训练。 由于 phrase grounding 的输入和 GLIP 的形式一样,都是输入一个句子和一张图片,将句子中的单词和图片中的位置相匹配,因此不需要对模型和损失函数进行任何调整。 同时,本文还采用了 self-training 的方式来增加训练数据以获得更好的模型性能。本文首先使用了现有的 phrase grounding 和 objection detection 人工标记数据集(一共 3M)预训练了一个 $teacher$ GLIP。 然后使用该 $teacher$ GLIP 对网上爬取的数据(图像-文本对,一共 24M)进行伪标签标记(即为文本中的每个名词预测对应图像的位置,每个文本的名词可以由 NLP parser 解析)。 最后,使用人工标记数据集(3M)和伪标签数据集(24M) 重新训练一个 $student$ GLIP-L,则这个 $student$ GLIP-L 就具有很强的性能(大大强于 $teacher$ GLIP)。
关于为什么 $student$ GLIP-L 会比 $teacher$ GLIP 性能强(明明它也是在 $teacher$ GLIP 训练的数据集和预测出的结果上训练得到的)有一个比较直观的解释: 本文假设 $teacher$ GLIP 是利用语言上下文和语言泛化能力来准确地建立它可能不知道的概念,比如疫苗,它可能对于疫苗直观概念并不知道,而是通过整个句子的上下文来定位到图像中的位置, 句法结构等丰富的语言语境可以为模型进行“有根据的猜测”提供有力的指导(比如它识别到了图像中的几个物体,但是其他的物体都已经和句子中的其他词匹配好了,只剩下疫苗物体和疫苗单词,此时即使模型不知道疫苗概念,也能匹配成功), 但本质上它还只是猜的,并没有学习到这个概念,对于下次同样的类别可能就会判断错误。但是当我们训练 $student$ GLIP-L 时,$teacher$ GLIP 的“根据经验猜测”变成了“监督信号”,就使得 GLIP-L 能够学习疫苗的概念。 因此 $student$ GLIP-L 会比 $teacher$ GLIP 性能强。
针对问题 3,其实 GLIP 使用图像-文本相似度的方式训练已经可以让模型学习到 language-aware 的图像表征,但是仅仅只是在模型最后进行 late-fusion (即点乘)还是不够的, 还应该在模型中间添加 middle-fusion 以促进模型更好地学习图像和文本之间的关系。 具体而言,如图,GLIP 在 Text-Encoder 和 Image-Encoder 的最后 $L$ 层使用 cross-modality communication 对两者的特征进行 deep fusion(假设 Image-Encoder 是 DyHead,Text-Encoder 是 BERT):
其中,$L$ 是 DyHead 中 DyHeadModules 的数量,BETRLayer 是在预训练好的 BETR 上新增的 BETR Layers。 $O^0$ 和 $P^0$ 分别表示 visual backbone 和 language backbone(BETR) 编码的特征。而 X-MHA 是 cross-modality multi-head attention module:
其中 $\{W^{(symbol, I/L)}:\ symbol \in {q,v,out}\}$ 都是训练参数,与 MHA(Transformer 中的多头注意力机制) 中的 query, value 和 output linear layer 相似。
最终,经过上述的 3 点改进,GLIP-L 获得了很强的目标检测性能并实现了 open-vocabulary 和 zero-shot 的能力。