
MQ-Det
Published:
论文题目:Multi-modal Queried Object Detection in the Wild
发表会议:Conference and Workshop on Neural Information Processing Systems (NeurLPS 2023)
第一作者:Yifan Xu (MAIS, Institute of Automation, Chinese Academy of Sciences)
Question
如何使用尽可能少的改动和计算量,在 language-queried-only detector 中添加 vision query 来进一步增强模型的检测能力。
Method
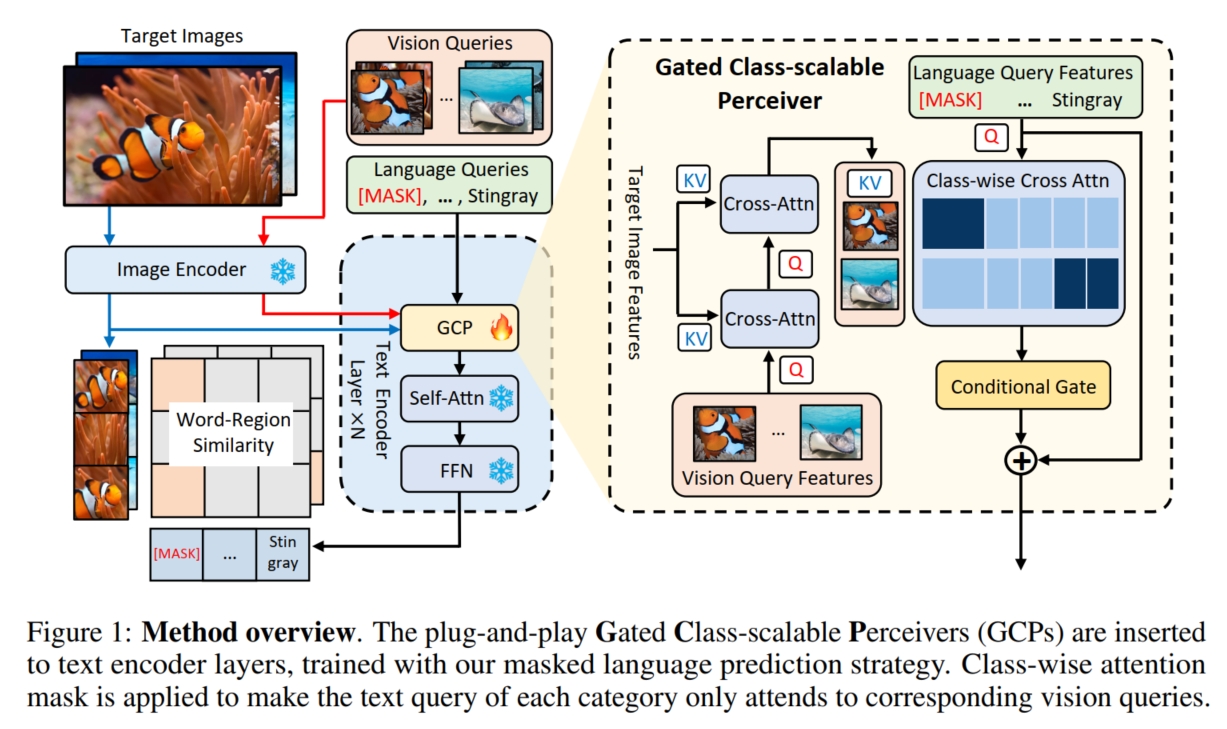
传统的 language-queried-only detector, 如 GLIP, 通过使用 language query 来实现对任意物体的检测 (即 open-vocabulary detection)。 但是这种方法依旧存在 1 个问题,那就是 text 的细节不如 image,它们通常拥有很高的信息密度,但是在细节方面没有 image 那样有足够的细粒度, 因此仅仅只使用 text 来引导模型对图像进行目标检测是不够的。 此外,根据上述分析,text 和 image 之间的优势是互补的,所以能同时利用它们两个来引导模型进行目标检测,无疑对性能提升有很大帮助。 所以最直接的方法是使用 image-image+text 对的数据集从头训练一个模型,但是这种方法的代价太高了, 一种代价更小的方式是在预训练好的 language-queried-only detector 的基础上加入 vision query,并继续训练,使其成为一个 vision-language-queried detector。 本文便是采用这种方式实现 vision-language-queried detector,它使用预训练好的 GLIP 作为 language-queried-only detector, 并提出了一种 Gated Class-scalable Perceiver (GCP) 模块来使得 GLIP 模型可以额外输入 vision query 辅助模型进行目标检测。 具体而言,如图,假设原始的图像-文本对为 $(I,T)$,新增的 vision queries 为 $V = \{v_i | v_i = \{v_i^{(j)}\}_{j=1}^k\}_{i=1}^{|C|}$, 表示对每个类别抽取 $k$ 个样本作为该类的 vision query。 GLIP 的 Image Encoder 为 $\Theta_I(·)$,Text Encoder 为 $\Theta_T(·)$。 GCP 模块通过 multi-head attention (MHA) 和 conditional gate 来利用 vision query 实现对 text query feature 的增强:
其中,X-MHA(·,·) 的具体实现可以参考 GLIP, $\sigma = tanh(·)$ 表示规范化函数,$gate(·)$ 是一个三层的 MLP,它逐渐将特征维度逐渐降低到特定于层的可学习标量,用于评估 vision query 的好坏。 $v_i = \Theta_I(v_i)$ 表示经过 GLIP Image Encoder 编码得到的 vision feature, 它首先经过目标图像 $I$ 的增强获得一定的 content-aware 得到 $\bar{v}_i$, 接着通过将增强过后的 vision query $\bar{v}_i$ 与相应的 text query $t_i$ 相关联,实现从多个视图丰富 $\bar{v}_i$ 获得 $\hat{v}_i$。 然后使用 $gate(·)$ 来评估 $\hat{v}_i$ 的质量并通过 $\sigma(·)$ 函数选择其与 $t_i$ 相融合的比例。 最终输出融合了 vision 和 text query 的全新的特征 $\hat{t}_i$。 可以看到,GCP 模块是一个 plug and play 的模块,它并不改变原始模型的输出维度和大小 (如原始的 GLIP Text Encoder 输入 text query feature,输出 new text query feature;而 GCP 输入 text + image query feature 和 target image feature, 输出 new text-image query feature,它和原始的 new text query feature 的维度和大小都相同),因此可以插入在任何地方。 本文将它插入到 GLIP 的 Text Encoder 的每个 Transformer Block 的最前面(即 MHA 之前)。这样每个 Block 都能融合 text query 和 image query,更有利于模型学习 (因此前述的 MLP 的特定于层的标量指的是特定于每一个 Transformer Block,即每个 Transformer Block 中的 GCP 模块都学习一个自身最合适的特征维度标量)。
如果仅仅只是将 GCP 模块加入到 pre-trained GLIP 中,然后对整个模型继续训练,一方面计算量还是有些大,另一方面由于含有 text-image query 的数据集较少, 只在这种数据集上进行训练,很可能会导致 catastrophic forgetting。因此,本文提出了 Modulated pre-training 的训练方式。 具体而言,MQ-Det 训练时 freeze 原始 GLIP 的模型参数,只训练新增的 GCP 模块的参数。 同时,为了解决 learning inertia 问题(即训练过程中模型始终在原始预训练的最优点附近徘徊,导致没有学习到融合的 vision query),MQ-Det 提出了一种简单的 mask 策略: 给定一个图像-文本对 $(I, T)$,将 $T$ 中的与 $I$ 中的目标物体相对应的单词使用一个 $[MASK]$ token 随机掩码,形成 $T = \{t_1,...,[MASK],...,t_{|C|}\}$, 掩码概率为40%(即掩码掉 $I$ 的 ground truth)。 使得模型被迫从 GCP 模块中的 vision query 中提取视觉线索,以提供准确的预测,从而增强模型对视觉查询的依赖。
最后,训练得到的 MQ-Det 就可以输入 image 和 text query 对任意图像进行目标检测了。