
Emu series (Emu & Emu Edit & Emu Video)
Published:
本文主要对近期 Meta 发表的三篇关于视觉处理的文章(Emu 系列)进行论文解读(按照它们的发布顺序): 首先是 SOTA 的 text-to-image 生成模型 Emu;接着以它为 baseline,进行 image edit 的研究改进,提出了一个大一统的图像编辑模型 Emu Edit, 这基本上就把图像领域主流的任务都刷了个遍。最后又提出了 Emu Video 模型,利用 Emu 完成了对 text-to-video 生成模型的改进,也获得了 SOTA。 (ps:我猜下一步应该就是 video edit 的研究改进了🙂)
论文题目:Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
论文题目:Emu Edit: Precise Image Editing via Recognition and Generation Tasks
论文题目:Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
发表会议:三篇论文都发表在 Conference of Computer Vision and Pattern Recognition (CVPR 2023)
第一作者:Xiaoliang Dai & Shelly Sheynin & Rohit Girdhar (GenAI, Meta)
Preliminary
Diffusion Model (DM):扩散模型是近年来最热的图像生成思想。 将任意一张图像 $I_0$ 进行噪声添加,每次添加一个服从 $N(0,1)$ 分布的随机噪声 $\epsilon_t$,获得含有噪声的图像 $I_t$,则进行了无数次后,原本的图像就会变成一个各向同性的随机高斯噪声。 按照这个理论,我们对一个各向同性的随机高斯噪声每次添加一个特定的服从 $N(0,1)$ 分布的噪声 $\epsilon_t'$,获得噪声量减少的图像 $I_t'$,则经过足够多次后便可获得一张逼真的图像 $I_0'$。 为此,我们可以选择任意一个图像生成模型 $M_G$ (例如 U-net 等),第 t 次时输入第 t-1 次生成的图像 $I_{t-1}'$,输出生成的图像 $I_t'$。 由于每次使用的是同一个图像生成模型 $M_G$,所以需要输入时间步信息 $t$ 来告诉模型现在是生成的第几步 (一个直观的理解是在随机噪声恢复成原始图像的前期,模型更关注图像的整体恢复,而后期则更加关注图像的细节恢复,所以需要时间步信息告诉模型现在是偏前期还是后期)。 同时通过 $I_{t-1}$ 直接生成 $I_t$ 较为困难,因为它需要生成正确其每个像素值,而每次添加的噪声 $\epsilon_t$ 较容易预测。 因此可以更换为每次输入 $I_{t-1}$,模型预测第 $t$ 次所加的噪声 $\epsilon_t$。所以损失函数为 $L = E_{z_0, t, c_t, \epsilon \sim N(0,1)}[||\epsilon - \epsilon_{\theta}(z_t, t, c_t)||_2^2]$。 其中 $z_0$ 是原始噪声(即一开始输入的图像),而 $z_t$ 是第 $t$ 步输出的图像, $\epsilon_{\theta}(z_t, t, c_t)$ 为模型预测的第 $t$ 步所加的噪声。 更加详细的介绍推理可以参考 The Basic Knowledge of Diffusion Model (DM)或者 The Basic Knowledge of Scored-based Generative Model。
Stable Diffusion:是 DM 模型的一种改进形式。它将噪声推广到潜变量空间进行学习,使得模型的计算量大大降低。 同时通过 cross-attention 的方法添加条件,使得模型可以根据给定的条件(如 text)来生成指定的图像。 详细的介绍推理可以参考 Stable Diffusion。
Emu
Question
如何使得 Diffusion Model (DM) 可以生成高质量的图像,同时又保持其泛化性(即能够生成任意描述的图像)
Method
想要 DM 模型生成任意(即大范围)的高质量图像,最简单直观的方法是收集一个这样的数据集给模型训练,但这显然是不可能的。 因此,一般采用的方法是先在一个质量参差不齐的大规模图像数据集(通常是网上收集到的)上预训练一个 DM 模型(称为 pre-training)。 此时它具有了生成任意的图像的能力,即泛化能力,但是生成质量不够高。接着便设计一个方法(称为 post pre-training,即 fine-tuning),进一步改进模型的生成质量,同时又能保持模型的泛化能力。 本文便提出了一个简单好用的 post pre-training 方法(称为 quality-tuning)来改进模型的生成能力。 具体而言,本文首先使用 latent Diffusion Architecture (即 Stable Diffusion)作为生成模型, 并对其进行简单改进以增强其作为预训练模型的能力(即在没有 post pre-training 之前,就尽量将模型的性能提高。 因为本文发现,对于提出的 quality-tuning 方法而言,如果原先的预训练模型能力越强,这经过 quality-tuning 后的模型能力也会越强)。 模型的具体改动如下:
将 autoencoder 的 channel 数量从 4 提高到 16。
添加额外的 adversarial loss 进行训练。
将原始的 RGB 图像输入使用傅里叶特征变换将其变换到更高 channel 维度的输入。
增加 U-Net 模型的 channel 数量和 residual block 的数量。
使用 CLIP ViT-L 将图像转为 visual embedding;使用 T5-XXL 将文本转为 text embedding (text 是作为条件)。
然后使用 1.1 billion 的图像数据集来预训练模型。训练时使用逐步增大分辨率的方式,即最开始使用最小分辨率的图像,随着训练的进行不断增加高一级分辨率的图像,直到加到最高分辨率的图像。 这样可以引导模型在最开始时先学习图像的整体生成,后面再不断学习图像的细节生成。 同时,在预训练的最后阶段,使用 noise-offset 技术($offset = 0.02$)来训练模型,促进模型生成高对比度的图像。
接下来,本文使用 quality-tuning (即 fine-tuning) 方法来改进模型的生成质量。 quality-tuning 方法的关键是构造一个小型但是质量极高的数据集来 fine-tuning 模型,因此 fine-tuning数据集必须包含以下性质:
fine-tuning 数据集可以非常小,大约只有几千张图像。
数据集的质量需要非常高,因此不能使用完全的自动化数据选择,必须需要人工注释进行进一步选择。
这样,即使 fine-tuning 数据集很小,quality-tuning 方法不仅可以显著提高生成图像的质量,而且不会牺牲模型的泛化能力。 但是如何选择这样一个数据集是一个问题,因为高质量具有很强的主观性。为此,本文借鉴了摄影领域对高质量图像评判的一些标准来帮助选择图像,同时结合了 Automatic Filtering 和 Human Filtering 来尽可能保证选择的图像的质量。 具体选择步骤感兴趣的读者可以阅读论文 Section 3.3。
为什么仅仅只用几千张的高质量图像就可以很好地提高模型生成能力?本文给出的一个解释是其实在预训练后,模型已经具备了生成高质量图像的能力, 但是由于没有对其加以正确的引导,导致模型不知道什么图像算是高质量图像,就只能随机生成不同质量的图像。而对其使用少量的高质量图像进行 fine-tuning (即加以引导)后, 模型就能掌握高质量图像的一些常见的统计性质,从而限制了模型输出图像的质量。
因此,在 quality-tuning 阶段,本文使用 small batch size ($64$) 来 fine-tuning 模型, 同时使用 noise offet $=0.1$,并使用 early-stopping 来防止模型过拟合(即要求 fine-tuning 不超过 $15K$)。
Emu Edit
Question
如何提高 Instruction-based image editing model 的性能(即仅仅使用 Instruction/text 来对输入的图像进行编辑, 例如:输入文字“将图像的 xx 物体去掉/在 xx 位置添加一个 xx 物体”和一张给定的图像,就可以获得按照文字要求编辑后的图像)
Method
Instruction-based image editing 任务面临的最大问题是如何按照给定的文本要求精确地编辑给定的图像,即变动指定的位置,其他地方保持不变。 一方面是这个任务的范围太广(包括可以用文本描述的任意编辑问题)。 通常而言,不同的子任务会采用不同的方式:例如对于修改图像中的某个物体,可能会使用基于 mask 的方法,将其他地方掩码住,只保留指定修改的物体可以编辑; 而对于风格迁移任务(例如转化为素描风),则可能会使用基于 adversarial learning 的方法,给定需要转化的输入图像和任意一张目标风格图像,使用 GAN 的训练方式训练图像,使其完成风格转化。 另一方面是数据集较少,每个任务的数据集相较于传统的图像生成数据集都属于小型数据集。 为此,本文借鉴了 GLIP 的思想(ps:我猜的🙂,因为它们的想法比较像), 通过统一 $16$ 个任务的输入输出将其聚集为一个任务,从而训练一个 multi-task image editing model Emu Edit。
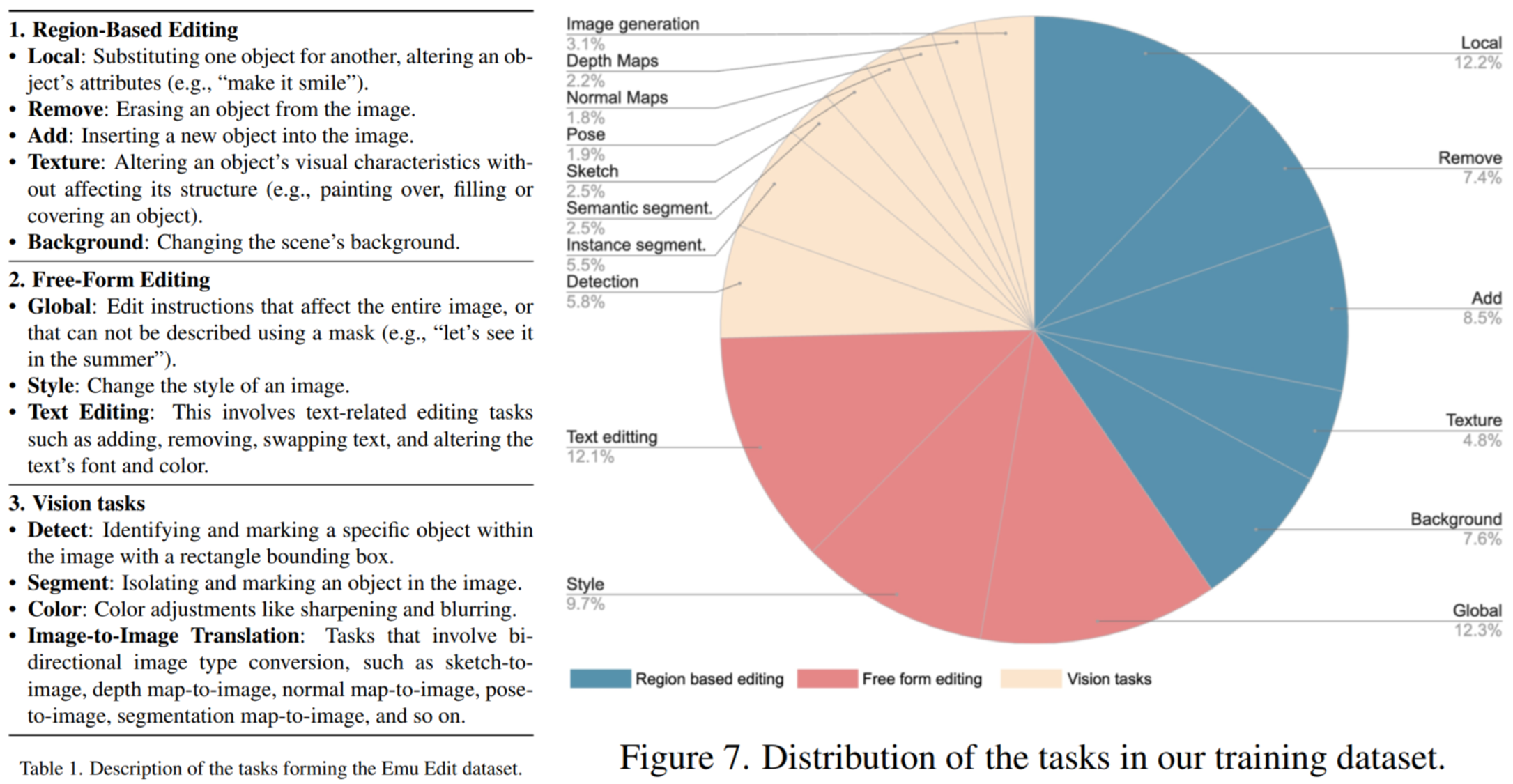
具体的$16$ 个任务如下图所示,主要包括 $3$ 个方面:Region-Based Editing,即仅对图像的局部进行编辑的任务;Free-Form Editing,即对图像进行自由编辑的任务(一般是全局编辑); Vision Tasks,即常见的传统视觉任务。对于每个任务,本文将它们的输入输出统一为 $(c_I, c_T, x, i)$:其中 $c_I$ 表示给定的输入图像(需要编辑),$c_T$ 表示给定的编辑 text (编辑要求), $x$ 表示编辑好的输出图像,$i$ 表示任务的编号($1 \sim 16$)。 与 GLIP 不同,本文并没有通过将这 $16$ 任务的原有数据集进行转化来获得一个统一的数据集,而是使用各个任务的 SOTA 模型生成伪数据构成数据集。 其基本思路包括多个方面,对应三个方向的任务数据生成。 对于 Region-Based Editing + Global + Text Editing,给定一个输入图像的标题 $T_I$,输出图像的标题 $T_O$,以及需要编辑的物体(通常存在在标题中) $O_e$,先使用模型根据 $T_I$ 生成输入图像 $C_I$, 然后根据 $C_I$ 和 $O_e$ 生成编辑好的输出图像 $C_O$,可以通过 P2P 模型实现。 对于 Style,先使用模型根据 $T_I$ 生成输入图像 $C_I$,再使用 PNP 模型来实现风格转化。 对于 Detect & Segment,先使用模型根据 $T_I$ 生成输入图像 $C_I$,再使用 DINO/SAM 模型生成检测/分割的区域,并直接对 $C_I$ 进行标记来获得输出图像 $C_O$。 对于 Color,先使用模型根据 $T_I$ 生成输入图像 $C_I$,再使用 color fliters & blurring & sharpening and defocusing 来获得输出图像 $C_O$。 对于 Image-to-Image Translation,先使用模型根据 $T_I$ 生成输入图像 $C_I$, 再使用 ControlNet 模型来实现图像转化。 这样就可以生成各个任务的统一格式的伪数据,并将它们组成一个新数据集。 可以看到,上述的生成过程至少需要 $T_I$,$T_O$ 和 $O_e$ 和任务 $i$。 本文借助了 LLM 的超强文本生成能力,通过为每个任务构造一个拥有上下文场景(包括任务和目的)的 agent,然后规定其输出格式(例如 JSON),并使用例子进行说明,然后引导 LLM agent 输出和例子相似的数据。 其输出的格式至少包括以下字段:一个编辑指令(editing instruction);一个输入 & 输出图像的标题(caption);需要编辑的物体的名字(object)。 caption 和 object 主要是作为生成数据时的输入,而 editing instruction 主要是作为训练时的输入。 因此,本文的数据集从头到尾都是生成的,包括需要编辑的图像的类型,编辑的类型,以及给定的编辑指令等。 在生成了数据集后,本文还使用多个自动过滤方法来提出低质量的图像,最终保留较高质量的图像。 具体的数据生成使用的模型和过滤方法等可以参考原文。
在获得了数据集(格式为 $(c_I, c_T, x, i)$)后,本文便使用 DM 模型来生成编辑后的图像,而将输入图像 $c_I$,编辑指令 $c_T$ 和任务标签 $i$ 作为条件限制模型的输出。 具体而言,本文选择 Emu 模型作为 baseline,使用 encoder 将目标图像 $x$ 转化为潜变量 $z = E(x)$,并使用扩散过程将其转化为含噪潜变量 $z_t, t \in [1,...,T]$ 作为模型的输入。 对于输入编辑指令 $c_T$,本文将它作为条件,使用 Text Embedding encoder 将其编码为 embedding,然后使用 cross-attention 与 $z_t$ 进行交互学习; 而对于输入图像 $c_I$,本文首先使用 encoder 将其转化为潜变量 $y = E(c_I)$,然后将其和 $z_t$ 在 channel 维度进行 concat 作为输入,对应地模型的输入 channel 也需要增加, 其权重初始化为 $0$。同时使用 classifer-free guidance ($\gamma_I=1.5$ (image condition) & $\gamma_T=5.0$ (text condition)) 和 zero signal-to-noise ratio (SNR) 来促进模型学习。 这样获得的初级模型训练函数为:
\[\underset{\theta}{min} \mathbb{E}_{y,\epsilon,t}[||\epsilon - \epsilon_\theta(z_t,t,E(c_I),c_T)||_2^2]\]其中 $\epsilon \in \mathcal{N}(0,1)$ 表示添加的噪声,$y = (c_T,c_I,x)$。 但是有些时候模型对于任务的区分不是那么清晰(例如 Global 和 Texture),容易将它们混淆在一起,从而导致输出图像的质量降低。 为此,本文通过输入显式的任务标签来引导模型使用正确的编辑方式。具体而言, 本文借鉴 VQ-VAE 的思想,创建了一个 task embedding table (可训练的),每个任务标签 $i$ 对应一个 task embedding $v_i$,根据不同的输入选择对应的 $v_i$; 然后使用 cross-attention 与 U-net 进行交互,同时将其加入到原始输入 $concat(z_t,y)$ 中,与模型一同优化训练。因此,进阶模型的训练函数更新为:
\[\underset{\theta,v_1,...,v_k}{min} \mathbb{E}_{\hat{y},\epsilon,t}[||\epsilon - \epsilon_\theta(z_t,t,E(c_I),c_T, v_i)||_2^2]\]其中 $k$ 表示任务的数量,$y = (c_T,c_I,x,i)$。而在 inference 阶段,本文训练一个 Flan-T5-XL 模型来根据输入的编辑指令 $c_T$ 预测对应的任务标签 $i$。
使用显式的 task embedding 除了可以帮助模型更好地学习外,还能够方便模型对其他任务的扩展。 当想要将模型扩展到 $16$ 个任务之外的图像编辑子任务时(如图像修复等),可以保持模型的参数权重不变,初始化一个新的 task embedding $v_{new}$ (可训练的), 然后使用少量的该任务的训练样本来更新 $v_{new}$。在训练完成后,便可以将其加入到 task embedding table,成为一个新的任务。具体的训练函数如下:
\[\underset{v_{new}}{min} \mathbb{E}_{y,\epsilon,t}[||\epsilon - \epsilon_\theta(z_t,t,E(c_I),c_T, v_new)||_2^2]\]进一步地,当使用模型连续进行一系列的图像编辑任务(例如先在图像上添加一个物体,然后再在结果图像上修改风格等),其重构和数值误差很可能就会累计,导致后面的图像质量较差。 为此,本文在每一步 edit 之后都使用了 pre-pixel thresholding 步骤来筛选生成图像的像素值。 具体而言,在每一步 edit $s$ 中,模型生成编辑后的图像 $c_I^{s+1}$,而其输入图像为 $c_I^s$。本文设置一个阈值 $\alpha$,对于每一个像素 $p_{i,j}$ (表示第 $i$ 行,第 $j$ 列), 只有当输出图像的像素值和输入图像的像素值之差大于阈值时,才使用输出图像的像素值;否则抛弃输出图像所预测的像素值,使用原始输入图像的像素值,即:
\[c_I^{s+1} = \begin{cases}c_I^s, & if\ \bar{d} < \alpha \\ c_I^{s+1}, & otherwise \end{cases}; d = ||c_I^{s+1} - c_I^s||_1\]其中,$\bar{d}$ 表示经过低通滤波后的 $d$。本文选择 $\alpha = 0.03$。
Emu Video
Question
如何提高 text-to-video model 的性能,包括视频质量,视频一致性以及多样性
Method
相较于 text-to-image,text-to-video 任务更加困难,因为它涉及多帧图像的生成,同时还要保证图像之间的一致性(连续性)。 在 NLP 领域中,对于序列生成的问题通常使用自回归方法,即一次生成一个元素,然后以已经生成好的元素作为额外的条件信息来帮助模型生成下一个元素。 因此,本文假设增强条件信息对于高质量视频的生成也很重要,因为它本质上是一个时间序列生成问题。 但是如果使用自回归方法,则会大大增加生成时间和计算量(特别是对于 DM 模型这种一次生成就需要多次采样的模型)。 为此,本文使用另一个条件信息来辅助模型学习,即视频第一帧的图像。 为了实现仅使用 text 作为输入,又能实现图像作为条件监督, 本文将 text-to-video 任务分解为 $2$ 部分:第一部分是使用给定的 text 生成图像,作为视频的第一帧;第二部分是使用给定的 text 和第一步生成的第一帧图像,生成视频;同时,本文仅使用一个生成模型来生成图像和视频。 具体而言,如下图,本文选择 Emu 模型 $\mathcal{F}$ 作为 baseling。首先将模型 $\mathcal{F}$ 使用预训练好的 text-to-image model 进行初始化,使其能够生成高质量图像, 这样,我们就只需要关注第二部分的视频生成。然后,本文使用 video-text 对来继续训练模型,并将视频的第一帧 $I$ 作为图像条件来辅助模型学习 (即在训练时没有第一步生成图像阶段,而是直接使用 ground-truth 视频的第一帧作为第一步生成得到的图像)。 模型输入 text $p$ 和图像 $I$,预测输出对应的视频 $V \in \mathbb{R}^{T \times 3 \times H' \times W'}$ (包含 $T$ 帧)。 因为 Emu 是针对图像的 latent DM,所以需要针对其进行一定的改进以适应输入输出视频。 首先使用 image autoencoder 的 encoder 将每帧图像(独立地)都转化为潜变量 $X \in \mathbb{R}^{T \times C \times H \times W}$; 然后在去噪完成后,使用 image autoencoder 的 decoder 将每帧图像的潜变量(独立地)都转化回图像 $V \in \mathbb{R}^{T \times 3 \times H' \times W'}$。 而在去噪环节,首先将每帧图像的潜变量独立地进行加噪,获得含噪输入 $X_t$,然后使用 U-net 独立地对每一帧含噪图像的潜变量进行去噪。 为了增强各帧之间的信息交互学习,本文在 U-net 的每个 spatial convolution (空间卷积)后增加一个 1D 的 temporal convolution (时间卷积), 在每个 spatial attention (空间注意力) 后增加一个 1D 的 temporal attention (时间注意力),将它们初始化(identity kernels for convolution, zero for attention MLP layer), 然后保持原始模型的参数不变,仅训练这些新增的模块的参数。 而对于 image condition,本文将图像单独表示为一个视频,并使用 zero-pad 将其扩展为 $I_V \in \mathbb{R}^{T \times C \times H \times W}$ 的张量, 同时构造一个 mask $ M \in \mathbb{R}^{T \times 1 \times H \times W}$ 来指示图像所在的位置(图像所在的位置设为 $1$,其他位置设为 $0$), 最后将 $I_V, M, X$ 在 channel 的维度上进行 concat,作为模型的输入,这样就将 image 作为条件添加到模型训练中。
在训练策略上,Emu Video 和 Emu 类似,首先使用 multi-stage multi-resolution 的方式进行训练, 即在训练的第一阶段使用低分辨率的视频进行训练($256px,8fps,1s,70K\ iteration$),第二阶段使用高分辨率的视频进行训练($512px,4fps,2s,15K\ iteration$), 第三阶段,使用更高帧率的视频进行再训练($512px,4fps,4s,25K\ iteration$)。然后使用极高质量的小型视频数据集进行 fine-tuning。
在上述的训练过程中,模型 $\mathcal{F}$ 是在低帧率的视频输入下进行训练。 而在训练完成后,本文提出了 interpolation model $\mathcal{I}$ 将 $\mathcal{F}$ 输出的低帧率视频 $V \in \mathbb{R}^{T \times 3 \times H' \times W'}$ 转化为高帧率视频 $V' \in \mathbb{R}^{T_p \times 3 \times H' \times W'}, T_p = 37$。 $\mathcal{I}$ 的模型架构和 $\mathcal{F}$ 一样,因此它只能输入输出相同帧数的视频。 为此,和上述 Image condition 类似,本文将输入视频 $V \in \mathbb{R}^{T \times 3 \times H' \times W'}$ ($T$ 帧) 使用 zero-interleave 填充到 $\hat{V} \in \mathbb{R}^{T_p \times 3 \times H' \times W'}$ ($T_p$ 帧); 然后构造一个 mask $ m \in \mathbb{R}^{T \times 1 \times H \times W}$ 来指示有效视频帧所在的位置(有效视频帧所在的位置设为 $1$,其他位置设为 $0$), 最后使用 $\mathcal{F}$ 初始化,并也只训练 temporal convolution 和 temporal attention。
在 inference 阶段,给定一个 text prompt $T$,首先使用 $\mathcal{F}$ (不经过 temporal convolution 和 temporal attention) 输入 $T$ 和随机噪声 $I_\epsilon$ 输出生成的图像 $I$; 然后使用 $\mathcal{F}$ (经过 temporal convolution 和 temporal attention) 输入 $I$ 和 $T$ 以及随机噪声 $V_\epsilon$ 输出生成的视频 $V$, 最后使用 interpolation model $\mathcal{I}$ 输入低帧率视频 $V$ 和随机噪声 $V_\epsilon'$ 输出生成的高帧率视频 $V'$。
