
Multi-modality with Context
Published:
论文题目:Is Context all you Need? Scaling Neural Sign Language Translation to Large Domains of Discourse
发表会议:International Conference on Computer Vision (ICCV 2023)
第一作者:Ozge Mercanoglu Sincan (University of Surrey)
Question
如何解决 Sign Language Translation (SLT) 的视觉歧义问题,即同一个手语动作在不同语境下的语义不同,而不同的手语动作也可能在不同的语境下表示相同的语义
Method
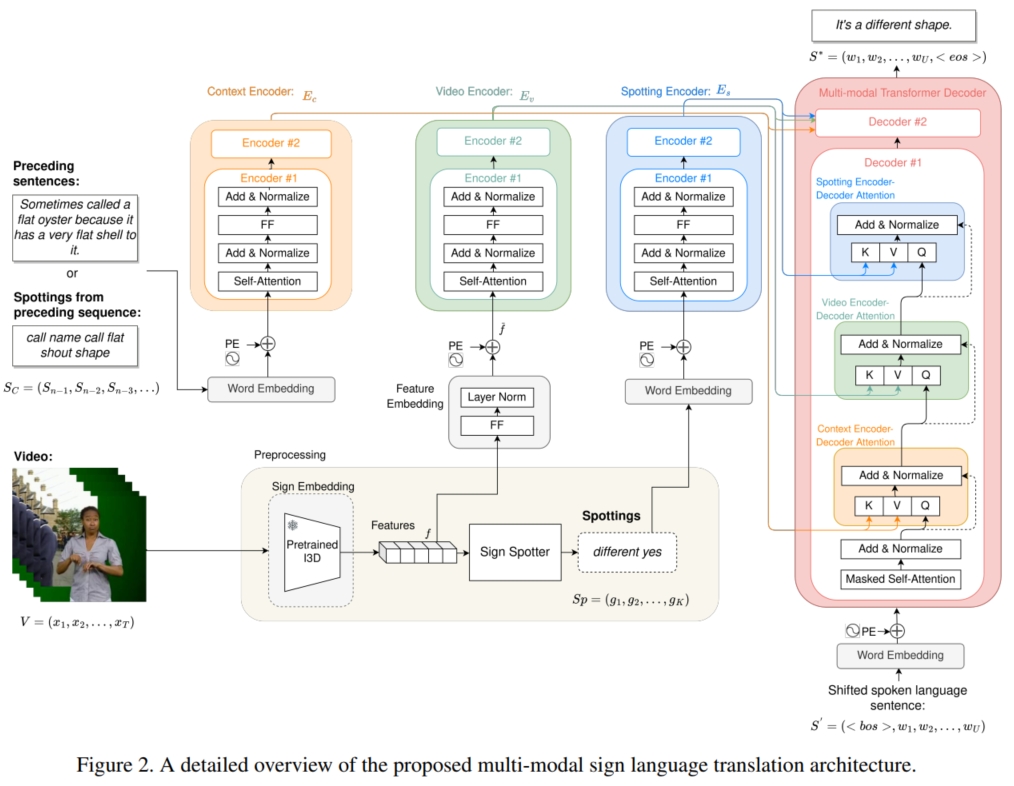
本文借鉴了人类处理歧义词的方式,主要是依靠上下文的综合理解来确定当前词的语义。 为此,本文提出了将之前已经翻译好的 sentence 作为 context 来帮助当前的 sign language video 的翻译。 但是 PHOENIX14-T 和 CLS-Daily 数据集中包含的是一个个打乱顺序的 video-gloss-sentence 数据对,导致其失去了连贯性,无法找到每一对数据的前一数据对。 因此,本文抛弃了上述的 $2$ 个数据集,使用最近新发布的 BOBSL 和 DSGS 数据集, 它们包含的是一整个连贯的视频段($V_1,...,V_M$)以及所对应的翻译 sentence($S_1,...,S_N$),来利用它们的 context 进行学习。
具体而言,给定一个手语视频 $V = (x_1,...,x_T)$,一个来自之前的上下文信息 $S_C = (S_{n-1},S_{n-2},...)$ (即之前的 sentence)和一个 sparse sign spottings $S_p = (g_1,...,g_K)$ (即 $gloss$)。 模型需要输入 $V$,并在输入 $S_C$ 和 $S_p$ 进行辅助学习下,预测输出翻译的 sentence $S = (\omega_1,...,\omega_U)$。 为此,如上图,本文使用 $3$ 个 Encoder $E_v,E_c,E_s$ 分别将 $3$ 个不同的输入编码为潜表示,然后使用 multimodal Decoder $D$ 融合 $3$ 个潜表示并解码预测 sentence $\hat{S}$。
首先,对于手语视频 $V$,本文使用预训练的 $I3D$ 模型将其转化为 embedding:将 $V$ 分割成帧长为 $L$ 的 video clips $c_t = (x_t,...,x_{t+L-1})$, 并使用 step size $= s$ 的步长从左到右对 $V$ 进行有重叠的 video clips 分割,获得 $V_{clip} = (c_1,...,c_{\frac{T-L}{s}+1})$; 然后输入 $I3D$ 模型生成 embedding $f_{1:\frac{T-L}{s}+1}$:$f_t = SignEmbedding(c_t)$。 为了避免维度不同导致的偏差,还需要将 $f$ 通过线性层进一步投射到特定的维度:$\hat{f}_t = FeatureEmbedding(f_t)$。 接着加上正弦函数的 positional embedding,获得最终的 embedding $\bar{f}_t = PositionalEncoding(\hat{f}_t)$。 然后输入到 Video-Encoder $E_v$ (Transformer Encoder),生成富含时空表征的 representation $h_{1:\frac{T-L}{s}+1}^v$。
其次,对于上下文信息 $S_C$,sign spottings $S_p$ 和 shifted target sentence $S'$ (即 Decoder 最开始的输入),本文采用预训练的 $BERT$ 模型将其进行 tokenization, 然后加上正弦函数的 positional embedding,获得获得各自的 embedding:$\bar{c},\bar{p},\bar{S'}$。 接着将 $\bar{c}$ 输入到 Context-Encoder $E_c$ (Transformer Encoder)生成 representation $h^c$,$\bar{p}$ 输入到 Spotting-Encoder $E_s$ (Transformer Encoder)生成 representation $h^s$。
然后使用 multimodal Decoder $D$ 融合 $h^v,h^c,h^s$ 和 $\bar{S'}$ 预测输出 sentence $S^*$。 具体而言,Decoder $D$ 包含一个 mask-MHA,用于输入 $\bar{S'}$ 的掩码输入;三个 cross-MHA,分别用于 $\bar{S'}$ 与 $h^v,h^c,h^s$ 的注意力计算; 一个 FFN 用于进一步更新交互后的 $\bar{S'}$。最后,将 Decoder 的输出使用线性层投射到 vocabulary size 的维度,并使用 cross-entropy 计算损失进行训练。
总结而言,模型的前向传播过程如下: