
PGen
Published:
论文题目:Scaling Back-Translation with Domain Text Generation for Sign Language Gloss Translation
发表会议:European Chapter of the Association for Computational Linguistics (EACL 2023)
第一作者:Jinhui Ye (HKUST(GZ))
Question
如何解决 Sign Language Gloss Translation (SLGT) 的数据缺乏问题
Preliminary
SLGT:gloss 是手语的一种书面形式,它通常是通过手语视频翻译而来,其中每个词语和手语视频中的每个动作都一一对应。 通常而言,gloss 会比 sentence (即我们日常说话使用的语句)更加简洁,同时因为它是按手语视频的动作及顺序翻译而来的,因此和 sentence 拥有不同的语法规则, 但是它拥有和 sentence 相似甚至相同的字典集(即它们所用的词汇表是相似/相同的)。 例如,对于正常的 sentence "Do you like to watch baseball games?",表达成 gloss 就变成了 "baseball watch you like?"。 而 SLGT 任务就是要将 gloss 翻译为正常的 sentence,以便与普通人的交流。
Back-Translation (BT):Back-Translation 又叫 glossification。 它是 SLGT 的反向过程,即将正常的 sentence 翻译为 gloss,以便后续继续翻译为手语视频。
Method
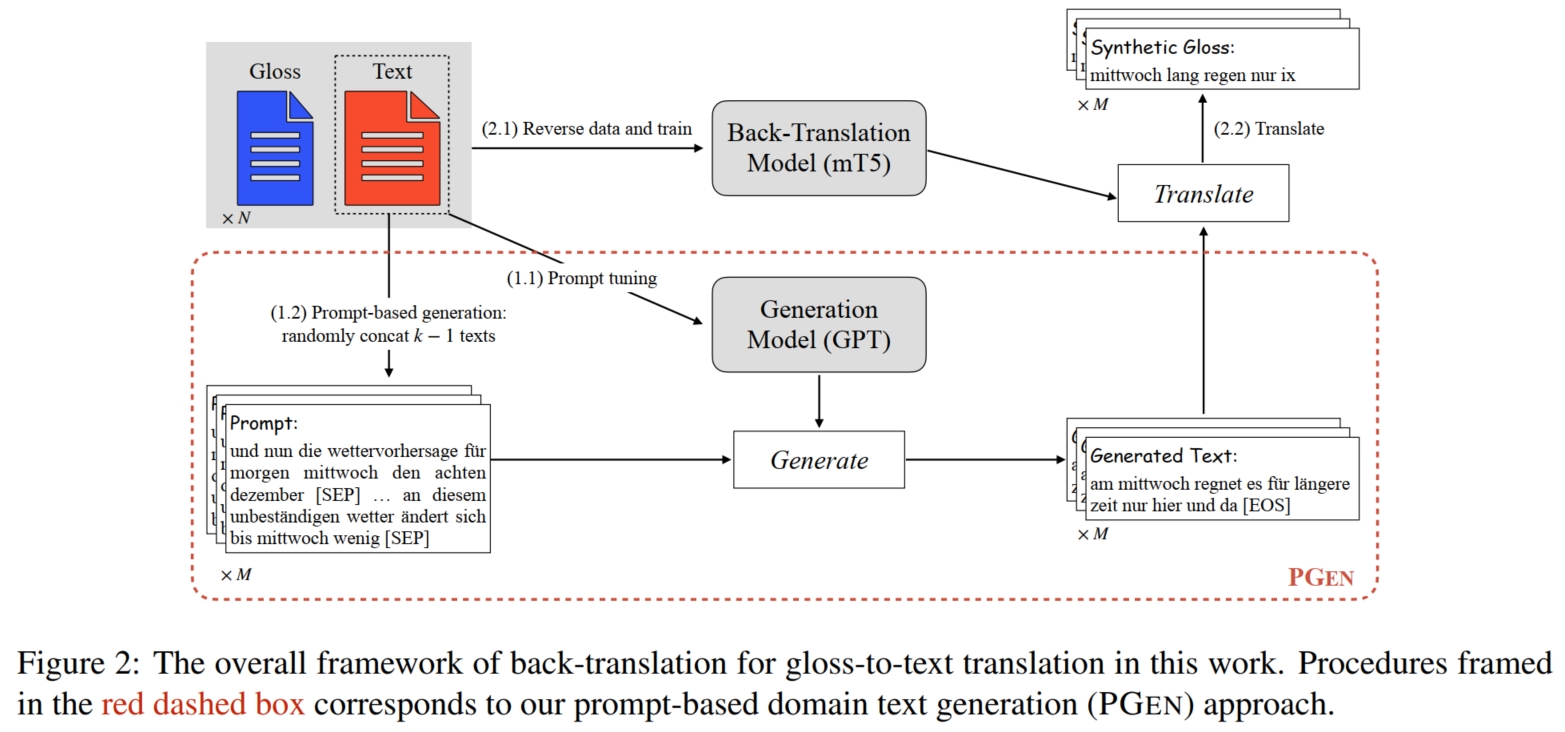
最近 LLM 的综合能力已经有目共睹,基本上胜任了 NLP 的所有任务。本文观察到 LLM 具有 $2$ 个重要的特性:
1) LLM 具有很强的记忆能力,能够记住训练数据的 knowledge
2) LLM 也具有生成大量新数据的能力,而不只是单单将它记忆的数据复制出来
根据这 $2$ 个特性,本文便想利用合适的 prompt 来引导 LLM 模型生成大量新的伪数据来帮助 SLGT 模型训练。 假设存在 SLGT 小型数据集 $D_{g2t} = \{(x^i, y^i)\}_{i=1}^N$,其中 $x$ 表示 sentence,$y$ 表示 glosses, 需要利用 LLM 生成伪数据集 $\hat{D}_{g2t} = \{(\hat{x}^i, \hat{y}^i)\}_{j=1}^M$。 最直观的方式是将 $\{x^i, y^i\}$ concat 起来作为 prompt 引导 LLM 模型生成相似的 $\{\hat{x}^j, \hat{y}^j\}$ 对。 但是由于 LLM 在运预训练时的训练数据中的 glosses 数据集很少,很可能甚至没有。 因此仅通过简单的 prompt 来让 LLM 模型学习很可能是不够的,最后导致其生成的 glosses $\hat{x}^j$ 的质量较低。 相反地,LLM 对生成正常的 sentence $\hat{y}^j$ 是十分擅长的。通常只需要给定几个 $y^i$ 作为 prompt,LLM 模型便能生成大量和 $y^i$ same domain 的伪数据 $\hat{y}^j$ (same domain 简单理解就是领域相似,比如都是英文的新闻天气预报句子)。 因此,与其让 LLM 生成质量较低的伪 $\{\hat{x}^j, \hat{y}^j\}$ 数据对,不如让 LLM 专心生成高质量的伪数据 $\hat{y}^j$。 然后通过其他方式来将生成好的 $\hat{y}^j$ 转化为 glosses $\hat{x}^j$,这样便可生成伪数据对 $\{\hat{x}^j, \hat{y}^j\}$。 为了进一步优化 LLM 模型的生成能力,本文采用了DA 中提到的 prompt tuning 方式微调 LLM 模型。 具体而言,首先在 $D_{g2t}$ 中随机选择 $k$ 个 sentence $y^{j_k}$ 并将其 concat 起来:$[y^{j_1},[SEP],...,y^{j_k},[EOS]]$。 然后提供 $[y^{j_1},[SEP]]$ 作为 prompt 引导模型继续生成剩下的句子,直到出现 $[EOS]$(即 GPT 的 auto-regression 训练方式,注意,这里是微调,需要根据 ground-truth 进一步更新 LLM 参数的)。 而对于如何将生成好的 $\hat{y}^j$ 转化为 glosses $\hat{x}^j$,最直接的方式是使用 BT 模型。 但是由于数据缺乏问题,使用 $D_{g2t} = \{(x^i, y^i)\}_{i=1}^N$ 直接训练 BT 模型可能也会导致最终生成的伪数据 $\hat{x}^j$ 质量较低。 为此,本文使用了在多语言数据集上预训练的 sequence-to-sequence 模型(如 mT5)来作为初始化 BT 模型(这样一来 BT 模型在一开始便有了较强的基础知识,后续仅需微调到特定任务即可)。 然后使用 $D_{g2t}$ 数据集训练 BT 模型,最终训练好的 BT 模型便可用来将生成好的 $\hat{y}^j$ 转化为 glosses $\hat{x}^j$。
总结而言,如上图,首先使用 $D_{g2t}$ 中的 $y^i$ 微调 LLM 模型; 然后使用 $y^i$ 作为 prompt (本文使用随机选 $k-1$ 个 $y^i$ 并 concat 起来:$[y^{j_1},[SEP],...,y^{j_{k-1}}]$, 然后引导模型生成第 $k$ 个伪数据 $\hat{y}^{j_k}$,这和微调 LLM 模型的数据组成一致) 来引导 LLM 模型生成大量的伪数据 $\hat{y}^i$; 接着使用 $D_{g2t}$ 微调预训练好的 BT 模型(mT5);最后使用训练好的 BT 模型将生成好的 $\hat{y}^j$ 转化为 glosses $\hat{x}^j$。