
SLTUnet
Published:
论文题目:SLTUNET: A Simple Unified Model for Sign Language Translation
发表会议:International Conference on Learning Representations (ICLR 2023)
第一作者:Biao Zhang (University of Edinburgh)
Question
如何解决 Sign Language Translation (SLT) 的数据缺乏和模态差异(video & text)问题
Preliminary
SLT:SLT 是要将手语视频(sign language video)翻译为对应意思的口语语句(spoken language text)。 通常有 $2$ 中实现方法:
1) $cascading$:它依赖于其他的中间表示,如 $glosses$ (gloss 是手语的一种书面形式,它通常是通过手语视频翻译而来,其中每个词语和手语视频中的每个动作都一一对应。 通常而言,$gloss$ 会比 sentence (即我们日常说话使用的语句)更加简洁,同时因为它是按手语视频的动作及顺序翻译而来的,因此和 sentence 拥有不同的语法规则, 但是它拥有和 sentence 相似甚至相同的字典集(即它们所用的词汇表是相似/相同的))。 然后将 SLT 任务分解成 $2$ 个子任务:sign language recognition 和 gloss-to-text translation。 其中,sign language recognition 是将手语视频翻译为 $glosses$ 序列(Sign2Gloss);而 gloss-to-text translation 则是将 $glosses$ 序列转化为对应的口语语句。 但是 $glosses$ 所表达的意思不完全等同于手语视频,通常会有信息丢失。
2) $end-to-end$:它直接使用单个模型将手语视频翻译为对应的口语语句,而不需要多阶段翻译。它存在 $2$ 个问题:一是数据集的缺乏;二是需要建模不同 modality 之间的联系。
Method
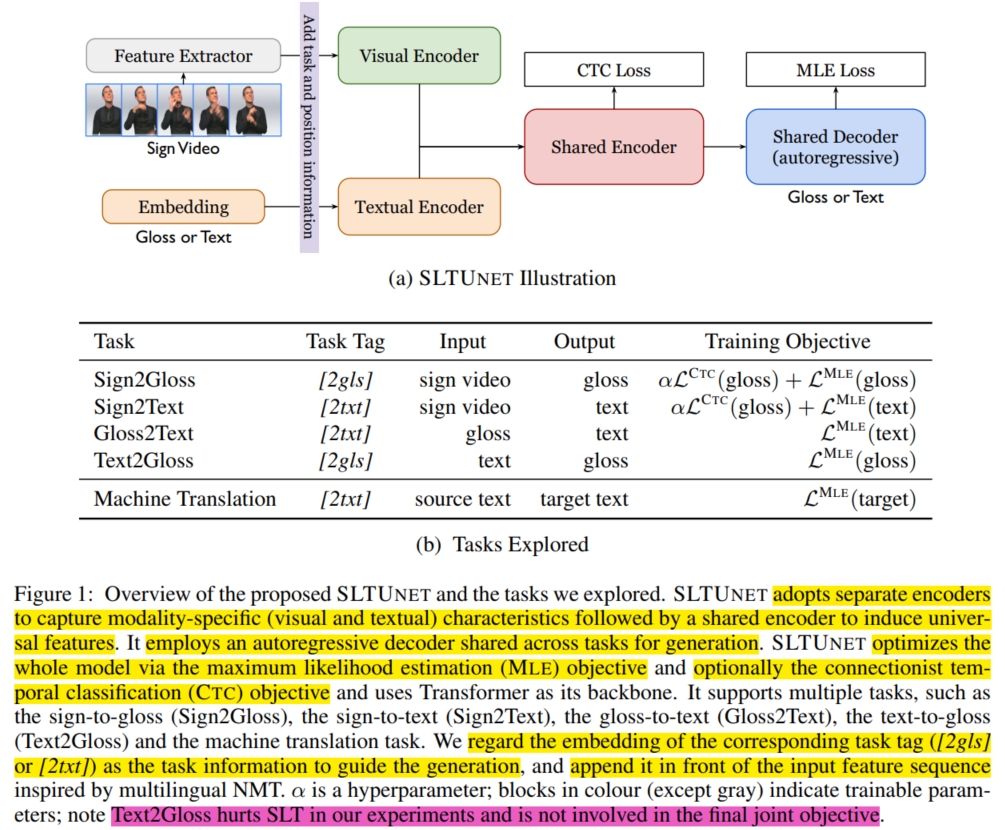
由于第一种方法的 $glosses$ 的局限性,所以单纯使用 $gloss$ 作为中间表示肯定不妥,但是 $gloss$ 数据的存在肯定对模型的训练有所帮助。 本文便提出如何将 $gloss$ 数据融合到第 $2$ 中方法中来缓解数据缺乏的问题。其次,对于不同 modality 的 gap,最常见的做法便是引入归纳偏置来使得模型学习到通用的特征。 而引入归纳偏置最有效的做法便是使用一个统一的模型来训练多个任务(包含多个模态),这样可以充分学习不同 modality 的特征,最终引导模型学习一个关于所有模态的统一特征(universal representation)。 因此,本文设计了一个统一的模型 SLTUnet,它囊括了 $Sign2Gloss$、$Sign2Text$、$Gloss2Text$、$Text2Gloss$ 和 $Machine\ Translation (MT)$ $5$ 个任务。 这样不仅可以融合大量的不同任务的数据集帮助训练,缓解数据缺乏问题,还有助于训练模型学习一个统一的特征。 具体而言,如上图,SLTUnet 包括一个 $Visual\ Encoder$、一个 $Textual\ Encoder$、一个 $Shared\ Encoder$ 和一个 $Shared\ Decoder$。 假设输入序列特征为 $X \in R^{|X| \times d}$,任务标签为 $tag$ (表示当前正在执行哪个任务,每个任务的 $tag$ 如上图表),输出序列为 $Y = \{y_1,...,y_|Y|\} \in R^{|Y| \times d}$ ($Y^I \in R^{|Y| \times d}$ 表示右移的输出序列,用于 Decoder 的输入)。 首先,SLTUnet 将任务标签 $tag$ 插入到输入序列特征的最前面 $X \in R^{|X| \times d}$ 作为输入 $\bar{X}$。 然后使用一个模态分离的 Enocder ($Visual\ Encoder/Textual\ Encoder$) 和 模态共享的 Encoder ($Shared\ Encoder$) 将输入 $\bar{X}$ 编码到潜表示 $X^O$。 最后使用共用 Decoder 模块 ($Shared\ Decoder$) 将潜表示 $X^O$ 解码为预测输出 $Y^O$:
对于任务 $Gloss2Text$、$Text2Gloss$ 和 $Machine\ Translation$ 来说,$Encoder^P(·)$ 是 $Textual\ Encoder$,而其输入序列特征 $X$ 是由 word embedding 得到的。 它使用极大似然估计损失(maximum likelihood estimation)进行训练:$L(Y|X, tag) = L^{MLE}(Y|Y^O)$。
而对于任务 $Sign2Gloss$ 和 $Sign2Text$ 来说,$Encoder^P(·)$ 是 $Visual\ Encoder$, 而其输入序列特征 $X$ 是由其他预训练视觉模型(如 $SMKD$)通过提取手语视频得到的(通常在提取到的特征后面增加一层线性层将其映射到特定的维度)。 它除了使用极大似然估计损失进行训练,还使用 CTC (connectionist temporal classification) 损失进行训练 (它通过边缘化 Decoder 的输入($X^O$)和 SLT 的中间表示序列($Z$,通常是 $glosses$)之间的所有有效映射来建模概率分布),并使用 $\alpha$ 来平衡两个损失:
最终,将这 $5$ 个任务联合起来训练便可获得高性能的 SLTUnet 模型。假设 SLT 数据样本为 $(\mathcal{V}, \mathcal{G}, \mathcal{T})$,MT 的训练样本为 $(S,T)$, 则训练函数可以表示为:
注意,这里删除了 $Text2Gloss$ 任务和 $Sign2Gloss$ 任务中的 CTC 损失(因为它们对最终的结果没提点,反而降点)。