
XmDA
Published:
论文题目:Cross-modality Data Augmentation for End-to-End Sign Language Translation
发表会议:截至2023年11月6日暂无,论文版本为 arxiv-v3
第一作者:Jinhui Ye (HKUST(GZ))
Question
如何解决 Sign Language Translation (SLT) 的数据缺乏和模态差异(video & text)问题
Preliminary
SLT:SLT 是要将手语视频(sign language video)翻译为对应意思的口语语句(spoken language text)。详见 SLTUnet 的 Preliminary。
Method
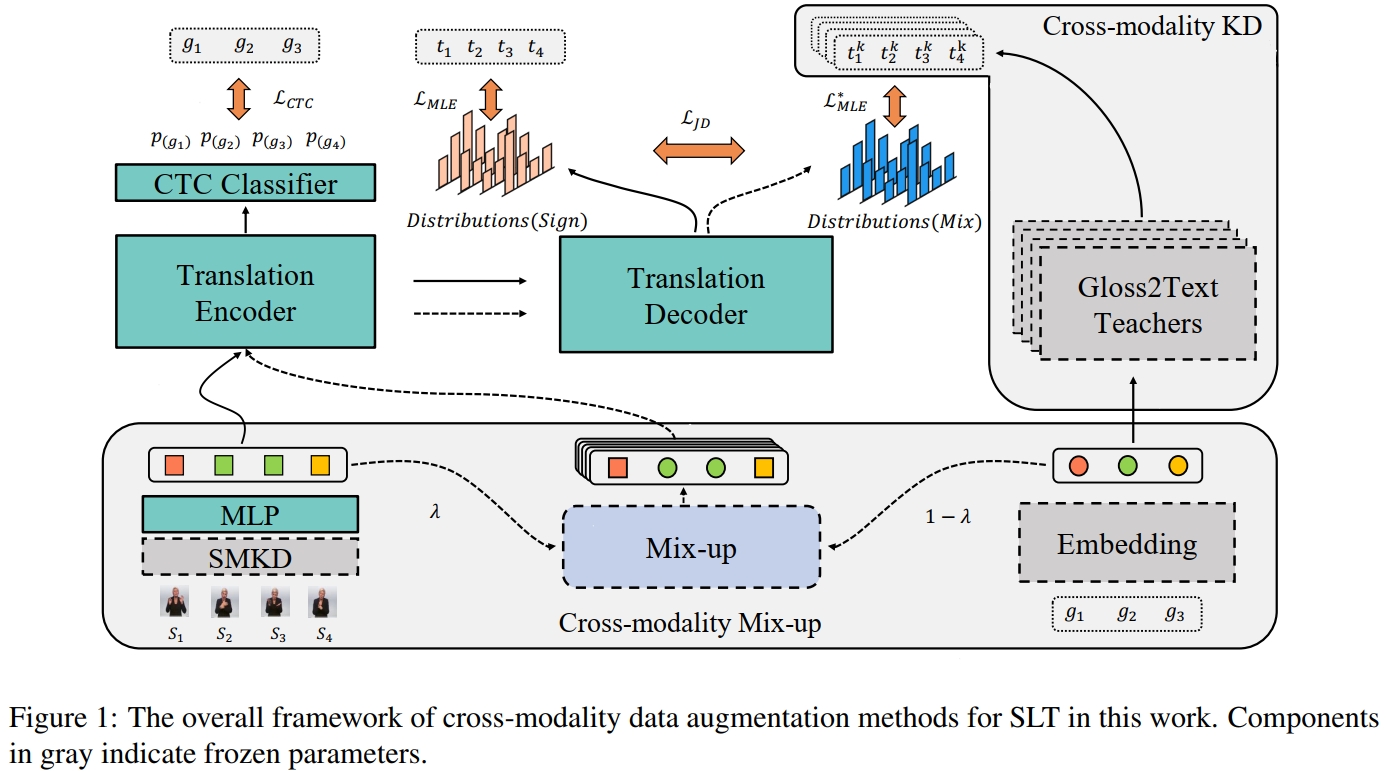
与 SLTUnet 相似, 本文也想通过合理利用 $glosses$ 数据来帮助 end-to-end 模型学习以减轻数据缺乏问题,同时使得模型能更好地学习模态融合特征。 因此,本文提出了 Cross-modality Mix-up 模块 和 Cross-modality Knowledge Distillation (KD) 模块来帮助模型学习。 假设 SLT 数据集为 $\mathcal{D} = \{(S_i, G_i, T_i)\}_{i=1}^N$,其中 $S_i = \{s_z\}_{z=1}^Z$ 表示手语视频,$G_i = \{g_v\}_{v=1}^V$ 表示对应的 $glosses$, $T_i = \{t_u\}_{u=1}^U$ 表示对应的 sentence。
本文使用的模型为 Sign Language Transformers。它主要包括 $5$ 个部分。 Sign Embedding 将手语视频编码为 sign embedding,本文使用预训练的 SMKD 模型,然后将编码后的 embedding 通过一层线性层投射到特定维度(与 gloss embedding 相同)。 接着,Translation Encoder 将 sign embedding 编码为 contextual representations $h(S)$。 然后,将 $h(S)$ 输入到 Translation Decoder 输出预测的 sentence $\hat{T}$,并使用 cross-entropy 损失进行训练:
此外,Sign Language Transformers 还包括 Gloss Embedding 和 CTC Classifer 模块。 其中, Gloss Embedding 类似于 word embedding,它使用一个 embedding 矩阵将 $gloss$ token 转化为向量表示。 而 CTC Classifier 是将 $gloss$ 作为中间的监督信号来训练 Translation Encoder。具体而言,它在 Translation Encoder 上增加了一个线性层和 softmax 函数来预测手语视频每一帧的 gloss 概率分布 $\mathcal{P}(g_z|h(S)), z\in [1,...,Z]$。 然后通过边缘化 $S$ 到 $G$ 之间的所有有效映射来建模概率分布:
其中,$G^*$ 是 ground-truth,$\pi$ 是预测的 $glosses$,而 $\Pi$ 是所有合法的 $glosses$ 集合。最后,CTC 损失函数为 $\mathcal{L}_{CTC} = 1 - \mathcal{P}(G^*|h(S))$。
对于 Cross-modality Mix-up 模块,它的主要作用是对齐 sign embedding 和 gloss embedding。 具体而言,Sign Language Transformers 的 Sign Embedding 将 $S = \{s_z\}_{z=1}^Z$ 编码为 sign embedding $\mathcal{F} = [f_1,...,f_Z]$, 而 Gloss Embedding 将 $G = \{g_v\}_{v=1}^V$ 映射为 gloss embedding $\mathcal{E} = [e_1,...,e_V]$。 Cross-modality Mix-up 通过将 $\mathcal{F}$ 和 $\mathcal{E}$ 结合在一起获得混合模态的 embedding $\mathcal{M}$。 首先,本文使用 CTC classifier 作为 sign-gloss forced aligner,通过最大化 $\pi$ 的边缘概率来计算每个 gloss token $g_v$ 对应的手语视频的起始点 $l_v$ 和终止点 $r_v$:
在求解得每个 $g_v$ 对应的 $l_v$ 和 $r_v$ 之后,通过一个预定义的阈值 $\lambda$ 来混合 $\mathcal{F}$ 和 $\mathcal{e}$ 以获得 $\mathcal{M}$:
注意,虽然 $\mathcal{M}$ 的下标标记到 $V$,但是其实际上的元素个数为 $Z$,因为其中的一部分 $m_i$ 的元素个数不是 $1$,而是 $(r_v - l_v + 1)$ 个。
由于 Cross-modality Mix-up 的主要目的是对齐 $\mathcal{F}$ 和 $\mathcal{E}$, 因此,本文首先将 $\mathcal{F}$ 和 $\mathcal{M}$ 都送入 Traslation Encoder 和 Decoder 预测输出 $\hat{T}_{\mathcal{F}}$ 和 $\hat{T}_{\mathcal{M}}$, 然后通过最小化两个预测概率分布的 Jensen-Shannon Divergence (JSD) 来进行正则化训练以对齐 embedding:
而对于 Cross-modality KD 模块,它的主要作用是利用现有的 gloss-text 模型作为 teacher 来帮助 Sign Language Transformer 学习。 具体而言,本文将现有的 gloss-text 模型作为 data augmentation 的工具。首先,使用数据集 $\mathcal{D} = \{(S_i, G_i, T_i)\}_{i=1}^N$ 训练 $K$ 个 gloss-text 模型 $M_{G2T}^1,...,M_{G2T}^K$, 然后,使用这 $K$ 个 gloss-text 模型分别对数据集中的每个 $G_i$ 进行翻译,获得 $K$ 个具有多样性的 sentence $\{T_i^1,...,T_i^K\}$, 接着,结合对应的 $G_i$ 和 $S_i$,以及原数据集,组成新的数据集 $D_{\mathcal{MKD}} = \bigcup_{k=0}^K(S_i, G_i, T_i^k)_{i=1}^N$ (其中 $T_i^0$ 表示原数据集) 用于训练 Sign Language Transformers。
总结而言,如上图,首先使用 Cross-modality KD 将 数据集 $\mathcal{D}$ 扩充成 $\mathcal{D}_{\mathcal{MKD}}$, 然后,在训练期间,使用 Cross-modality Mix-up 来生成额外的混合模态 embedding $\mathcal{M}$,并使用 $\mathcal{L}_{JSD}$ 进行 embedding 对齐, 接着对 embedding $\mathcal{F}$ 使用 $\mathcal{L}_{MLE}$ 和 $\mathcal{L}_{CTC}$ 进行训练,而对 mixed embedding $\mathcal{M}$ 使用 $\mathcal{L}_{MLE}$ 进行训练。 最后,在推理期间,使用 Sign Embedding 将手语视频 $S$ 编码为 sign embedding $\mathcal{F}$, 然后输入 Translation Encoder 进行进一步编码输出 contextual embedding $h(S)$,然后将 $h(S)$ 输入 Translation Decoder 进行解码输出预测的 sentence $\hat{T}$ (没有使用 CTC classifier, Gloss Embedding,gloss-to-text 模型以及 Cross-modality Mix-up & KD)。