
The Basic Knowledge of PyTorch Distributed
Update:
Published:
这篇博客主要介绍了 LLM 分布式并行的训练方式,并着重讲解了 PyTorch 代码的实现 DDP 的方式。
LLM Train Overview
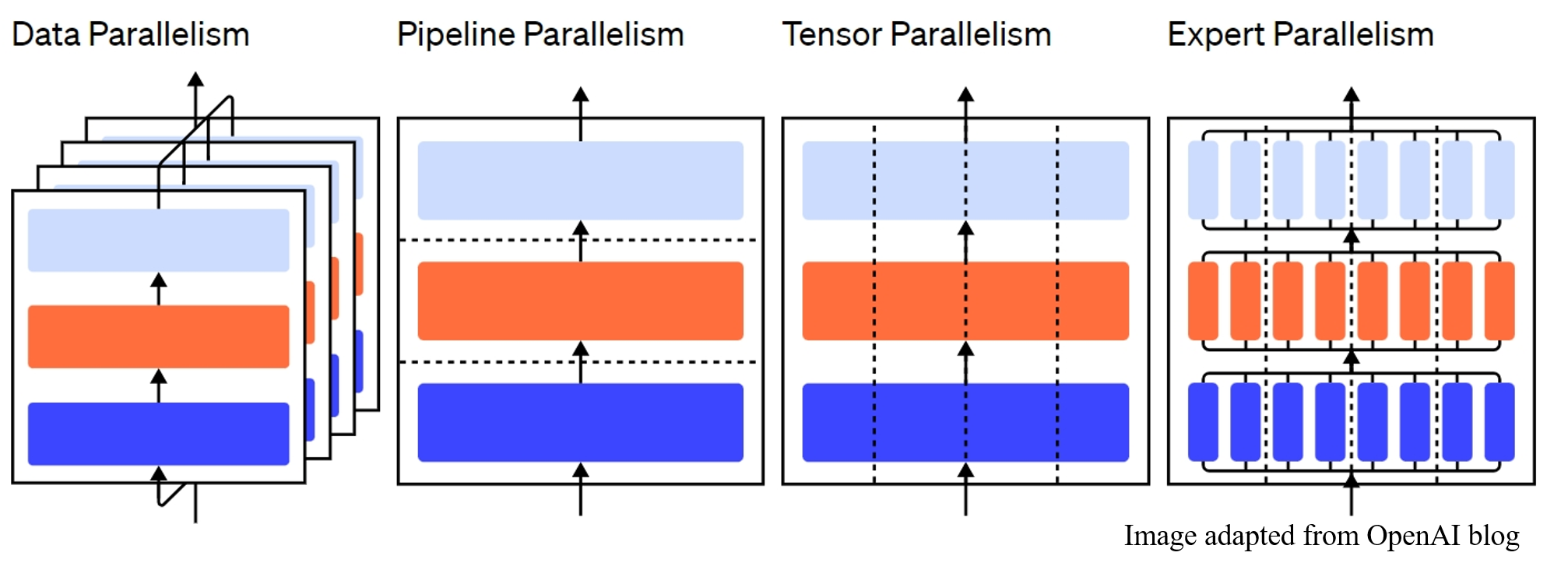
Large Language Model 的训练需要众多 GPU 或其他 AI accumulator 的联合训练(即 GPU 集群)。 通过将不同维度分布到 GPUs 上,可以实现不同的并行训练方式。 具体而言,主要包括 Data Parallelism、Pipeline Parallelism、Tensor / Model Parallelism 和 Expert Parallelism。
首先回顾一下在单个 GPU 上训练模型的范式。 通常而言,主要包括 $3$ 个步骤:
- 使用输入(inputs)和标签(labels)前向(forward)通过模型,计算损失(loss);
- 使用损失后向(backward)通过模型,计算模型每个参数的梯度(gradient);
- 使用优化器(optimizer)根据 gradient 对模型参数进行更新。
具体而言,首先输入 $X \in \mathbb{R}^{B \times N}$ 和 $label \in \mathbb{R}^{B \times 1}$ forward 模型 $\mathbf{M} \in \mathbb{R}^{L \times D}$, 得到损失 $\mathcal{L} = \mathbf{M}(X, label) \in \mathbb{R}^{B \times 1}$。 然后使用 $\mathcal{L}$ backward 模型得到每个参数的梯度 $\mathcal{G} = BP(loss) \in \mathbb{R}^{L \times D}$。 最后使用 optimizer 根据 $\mathcal{G}$ 对模型 $\mathbf{M}$ 参数进行更新:$\hat{\mathbf{M}} = \mathbf{M} - \eta \times \mathcal{G}$。
由上述单 GPU 训练过程可以看到,该训练范式存在多个可以进行划分的维度:
将 $B$ 进行划分($B = [B_1,...,B_M]$),然后将不同的输入数据 $X_m \in \mathbb{R}^{B_m \times N}$ 和 $label_m \in \mathbb{R}^{B_m \times 1}, m = [1,...,M]$ 分布到不同的 GPU 进行计算,即可得到 Data Parallelism;
将 $N$ 进行划分($N = [N_1,...,N_H]$),然后将不同的输入数据 $X_h \in \mathbb{R}^{B \times N_h}$ 和 $label_h \in \mathbb{R}^{B \times 1}, h = [1,...,H]$ 分布到不同的 GPU 进行计算;即可得到 Sequence Parallelism (实际上等价于 Tensor / Model Parallelism);
将 $L$ 进行划分($L = [L_1,...,L_I]$),然后将不同的模型模块 $\mathbf{M}_i \in \mathbb{R}^{L_i \times D}, i=[1,...,I]$ 分布到不同的 GPU 进行计算,即可得到 Pipeline Parallelism;
将 $D$ 进行划分($D = [D_1,...,D_J]$),然后将不同的模型参数 $\mathbf{M}_j \in \mathbb{R}^{L \times D_j}, j=[1,...,J]$ 分布到不同的 GPU 进行计算,即可得到 Tensor / Model Parallelism。
Data Parallelism (DP) $\rightarrow$ Distributed Data Parallelism (DDP)
通俗地讲,DP 将相同的模型参数复制到多个 GPU 上(通常称为 “worker”),并为每个 GPU 分配不同的数据(即 $\{X_m, label_m\}$)以实现同时处理。 具体而言,假设有 $M$ 个 GPU 可供训练,DP 首先在每个 GPU 上都存储一份模型参数 $\mathbf{M}$,然后为第 $m$ 个 GPU 分配第 $m$ 份训练数据 $\{X_m, label_m\}$。 接着执行下面操作:
- 独立计算每个 worker 关于对应数据 ${X_m, label_m}$ 的梯度 $\mathcal{G}_m$;
- 对所有 worker 的梯度进行收集并平均:$\mathcal{G} = \dfrac{\sum_{m=1}^M{\mathcal{G}_m}}{M}$;
- 在每个 worker 上独立使用 optimizer 计算新参数:$\hat{\mathbf{M}} = \mathbf{M} - \eta \times \mathcal{G}$。
因此,DP 本身仍然要求设计的模型适合单个 GPU 的内存(也就是在 batch_size $= 1$ 的情况下,模型必须能在单 GPU 的训练范式下成功训练,而不会爆 OOM), 只是允许利用多个 GPU 的计算能力来在单位时间内处理更多的训练数据(即处理更大的 $B$),且其代价是存储许多重复的参数副本(每个 GPU 都存储一份)。 同时,当每个 worker 更新其参数副本时,它们需要协调以确保每个 worker 在更新后仍然拥有相同的参数,即更新后的 $\hat{\mathbf{M}}$ 也应该相同。 最简单的方法是在 worker 的各个阶段引入阻塞式通信(block communication)。可以看到,步骤 $2$ 是一个求梯度平均值的操作,可以在这里进行阻塞通信, 即等到所有的 worker 都计算完成各自的梯度 $\mathcal{G}_m$,然后在进行通信获得平均的梯度 $\mathcal{G}$。 也就是说,对于任意一个 worker,在它计算完成自己的梯度之后,只能等待其他 worker 计算完成它们的梯度,并得到最终的均值梯度后,才能使用自己的 optimizer 进行参数更新并进行下一轮迭代。 这极大地阻碍了 GPU 计算资源的利用(因为在等待期间 worker 什么也没干,即空闲时间)。因此 PyTorch 实现更为复杂的通信方法来尽可能减少 worker 的空闲时间。
(注意:在 PyTorch 中,DP 和 DDP 都表示广义 DP 的实现方式,其中 DP 是在一台机器(即所有使用的 GPU 都在一台服务器内,无需考虑服务器间的通信)内的单进程多线程实现方式; 而 DPP 是在多台机器内的多进程实现方式。由于 DDP 方式较为先进,现在已经基本摒弃了 DP 方式,因此下面只讲解 PyTorch 在 DDP 方式上的实现。)
具体而言,由于 PyTorch 在 forward 过程中创建了一个自动求导图(autograd map), 一种简单的实现方式是 DDP 可以在 autograd map 的每个节点(每个节点表示一个参数)注册一个 hook (PyTorch autograd engine 接受自定义的 backward hook,类似于 flag),以便在每次 backward 后触发计算。 由于 backward 时是从上到下遍历 autograd map 并计算每个节点的梯度,因此,当计算完成一个节点后,其注册的 hook 便会触发(即 flag 值改变), 然后扫描所有 worker 中模型的对应节点,并从参数中检索梯度张量,即判断其梯度是否也已经计算完成。 然后,使用 AllReduce 集合通信调用来计算所有 worker 上每个参数的平均梯度,并将结果写回各自的梯度张量中。 总结而言,即对于模型 $\mathbf{M}$ 的每一个参数 $p_i$,都独立使用一个 AllReduce 集合通信调用来计算平均梯度 $\mathcal{G}_{p_i} = \dfrac{\sum_i}{p_i.grad}$, 然后将结果写回参数 $p_i$ 的 $.grad$ 属性中,并使用 optimizer 进行参数更新:$p_i = p_i - \eta \times p_i.grad$。 这样每个参数 $p_i$ 只需等待其他 worker 中的模型的对应 $p_i$ 参数的梯度计算,并且在 $p_i$ 通信期间,剩下的未计算完成梯度的参数 $p_{i-1},...,p_1$ 可以继续计算自身梯度, 实现了通信和计算资源的充分利用(即在同一时间内既存在计算也存在通信)。 但是对于高级的通信工具包来说(NCCL、Gloo、MPI),其通信能力和每次通信的数据量成正比,也就是说,每发起一次 AllReduce 集合通信时,如果传输的数据量越大, 则单位时间能传输的数据量就越大。(通俗理解就是由于发起 AllReduce 操作需要通信连接、缓存准备等很多前置和后置预操作(这些操作所需的时间一般不变),传输的数据越少,传输数据的时间也越小,则这些预操作的时间占比就会越大, 因此需要在一次 AllReduce 操作中传输尽可能多的数据)。
根据上述分析,不能等到所有梯度计算完成再一次性全部传输,也不能每个梯度都完成后就立刻传输。因此在 Pytorch v1.5 中, 其使用了 bucketing gradients + overlapping computation with communication 的块梯度传输方式进行改进:它将模型梯度进行分组操作,当每组内的所有梯度都计算完成后,使用一个 AllReduce 集合通信调用来计算平均梯度,而组与组之间的通信是独立的。 具体而言,首先,PyTorch 通过实验分析,发现了一般的模型的 backward (既计算梯度)的时间和高级通信工具包的通信时间(既计算平均梯度)具有相同的数量级。 这说明可以通过合理的设计实现 backward 和 communication 的时间重叠(既同一时间内,worker 既在计算梯度,也在通信梯度)。 然后,PyTorch 为每个参数的梯度累加器(gradient accumulator)注册一个 autograd hook,类似于 autograd map 的每个节点(每个节点表示一个参数)注册一个 hook。 hook 会在累加器更新梯度后触发,并检查它所属的组(bucket)。如果同一个组中所有梯度累加器的 hook 都被触发了,那么最后一个触发的 hook 将触发该组上的异步 AllReduce 操作, 计算所有 worker 的对应组的平均梯度,并将其写回组内的对应参数的梯度张量中。
这里存在 $3$ 个问题,即如何分组、如何保证每个 AllReduce 操作通信时的组时相互对应的以及如何处理子模型训练问题。
如何分组:PyTorch v1.5 选择将模型的连续参数组成一个组,比如对于 Transformer 来说,将每个 Transformer Block 的参数组成一个组,而不是所有的 self-attention 的参数组成一个组。并且,PyTorch v1.5 通过使用 model.parameters() 的逆序作为组顺序,因为在模型前向传递中,每个层都是按照调用的先后顺序构建的图。因此,它的反向顺序(即逆序)应该近似表示反向过程中的梯度计算顺序。
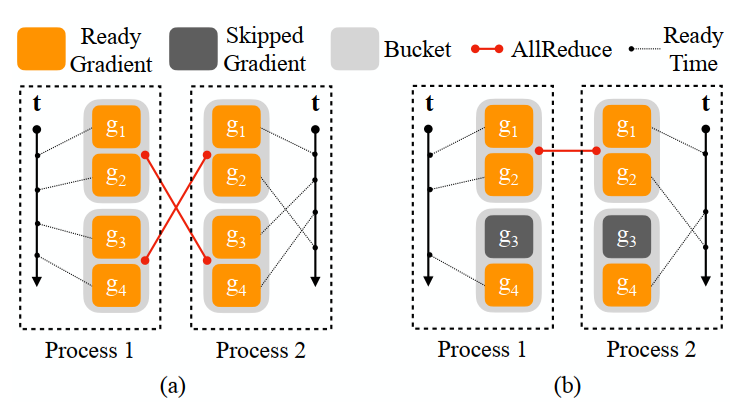
如何保证每个 AllReduce 操作通信时的组相互对应:因为上述实现中是只要一个组内的所有梯度均计算完成,便发起一个 AllReduce 操作。这就可能出现第 $i$ 个 worker 的第 $a$ 个组的梯度计算完成,发起一个 AllReduce 操作;而第 $j$ 个 worker 是第 $b$ 个组的梯度先计算完成,发起一个 AllReduce 操作,从而导致本次的 AllReduce 操作是第 $i$ 个 worker 的第 $a$ 个组的梯度和第 $j$ 个 worker 的第 $b$ 个组的梯度进行计算均值,造成计算错误。如下图 $(a)$ 所示。为此,PyTorch 规定所有 worker 必须使用相同的组顺序,并且在每个 worker 中,组 $i+1$ 无法在第 $i$ 个组之前启动 AllReduce。由于 1 中的组顺序近似反向过程中的梯度计算顺序,因此根据这种组的顺序依次启动 AllReduce 尽可能保证了计算和通信的重叠。
如何处理子模型训练:在模型训练时,有可能只训练模型的一部分参数,但是在分组时是将所有的参数进行了分组,这就有可能导致一个组内有部分参数本次不参与训练,也就没有计算梯度,而一个组发起 AllReduce 的条件是组内的所有参数都计算完成梯度,造成该组始终无法发起 AllReduce。如下图 $(b)$ 所示。为此,PyTorch 在 forward 过程构建好求导图后,又根据从上到下的顺序遍历一遍求导图,找到所有参与本次训练的参数,然后将剩下没参与训练的参数直接标记为 ready (即直接触发对应的 hook)。这样,在 backward 过程时,由于没参与训练的参数已经准备好,只需要每个组内的参与训练的参数计算完梯度,就能够发起 AllReduce 操作。
如何处理显式取消梯度求解:在 PyTorch 模型训练时,可以通过设置 required_grad = False 来显式要求取消该参数的梯度计算。与子模型不同,该参数通常也会存在在模型的 forward 计算中,即会存在在求导图中,无法通过遍历求导图进行剔除。同时,有可能每个 worker 的设置参数不一致(即 worker $1$ 设置 $p_1$ 的 required_grad = False;而 worker $2$ 设置的是 $p_2$ 的 required_grad = False)。此时,虽然 worker $1$ 的 $p_1$ 没有梯度,也需要发起 AllReduce 操作将其他 worker (如 $2$) 的 $p_1$ 的梯度进行求平均并进行梯度更新。为此,PyTorch 专门为其使用位图(bitmap) $B_i$ 来追踪每个参数的参与情况,然后发起一个额外的 AllReduce 操作来获得全局的位图,从而获得全局未使用的参数:$B_{global} = B_1 | ... | B_M$。其中位图表示每个参数是否需要求导,而将每个位图相与获得全局位图表示对于任意参数 $p_i$,只要 $M$ 个 worker 中有一个要求对其进行求导,则就表示它是需要求导的,后续需要发起 AllReduce 操作来对其进行平均梯度;而对于所有 worker 都无需求导的参数(即所有 worker 都设置其 required_grad = False),便无需对其进行求导和 AllReduce 操作。
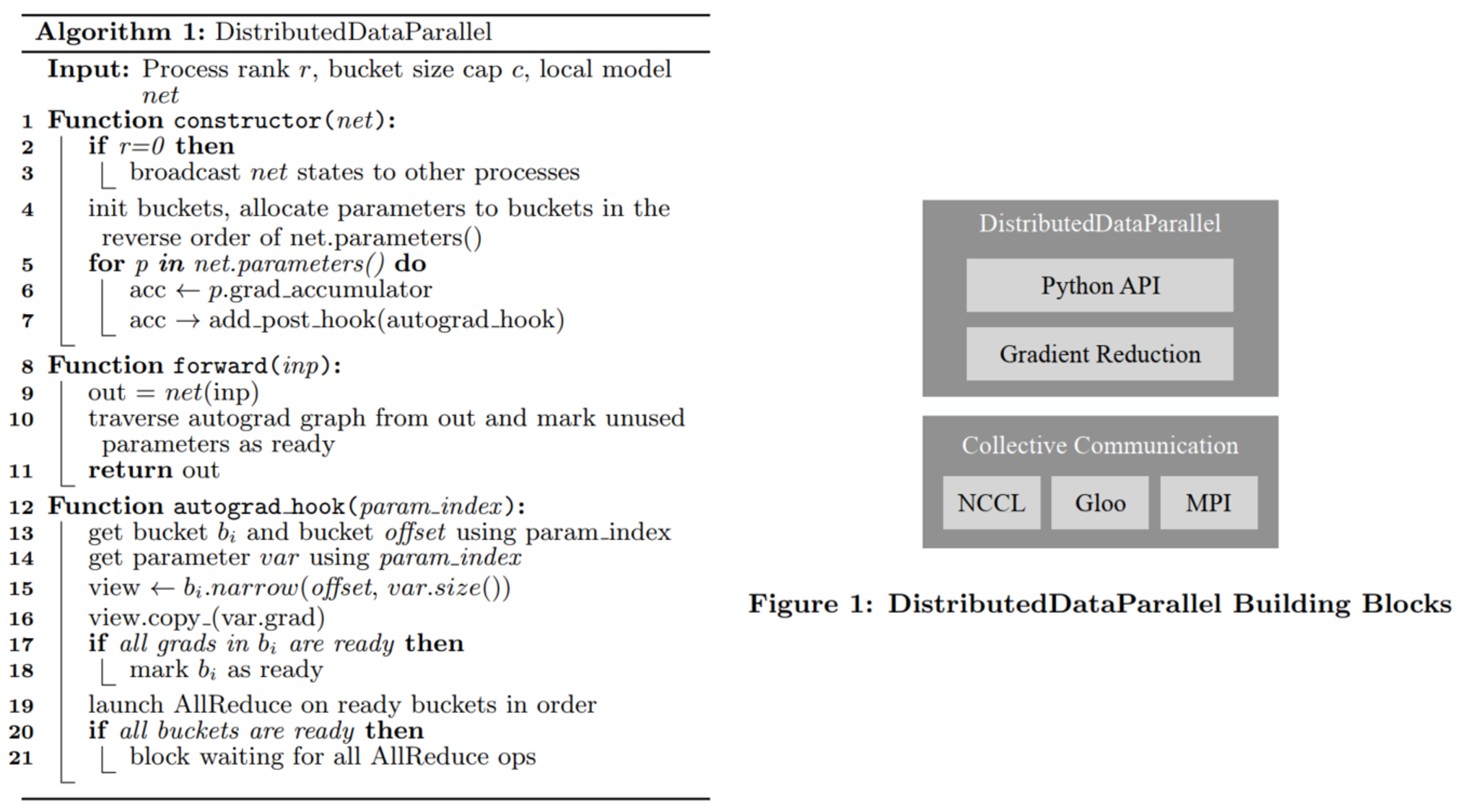
最终,PyTorch v1.5 的 DDP 算法实现和框架如下所示:
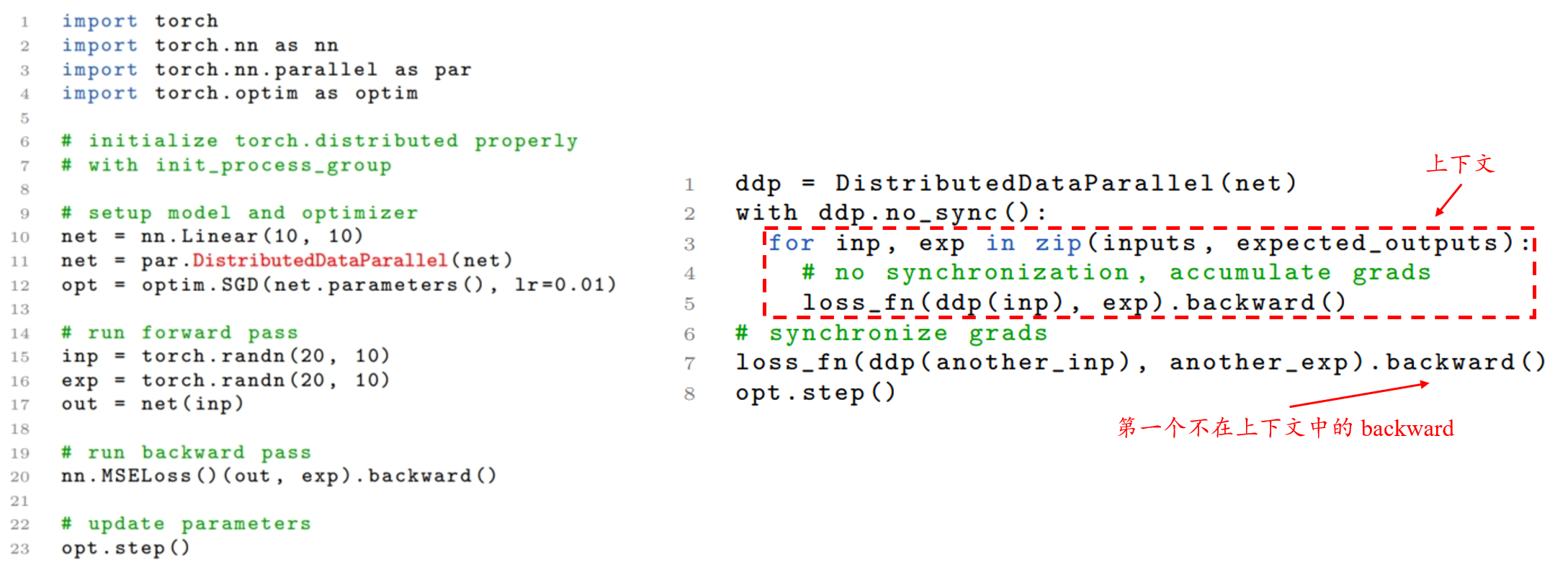
除此之外,还可以使用 skipping gradient synchronization 来进一步提高训练速度。 一种常见加速分布式数据并行训练的技术是降低梯度同步频率,即发起 AllReduce 的频率。因此,可以在全局同步梯度之前进行 $n$ 次局部训练迭代,而不是在每次迭代中都启动 AllReduce。 也就是进行多次模型的 forward 和 backward 操作,每次都将计算的梯度存在梯度累加器中;等到 $n$ 次之后才进行 AllReduce 计算平均梯度并更新参数。 PyTorch 实现了 no_sync() 来满足这种情况。在使用 hook 的情况下,no_sync 的实现非常简单。 只需要上下文管理器在进入和退出上下文时切换一个标志 $\mathcal{F}$,该标志管理前述的 hook 是否可用,它一般在 DDP 模式的 forward 函数中使用。 在 no_sync 模式下,即进入上下文时,设置 $\mathcal{F} = False$,表示所有的 hook 都被禁用; 直到退出上下文时,设置 $\mathcal{F} = True$,所有的 hook 都重新可用,此时出现第一个不在上下文中的 backward 时便会同步累积的梯度,即发起 AllReduce 操作。 同时,全局未使用的参数信息也会累积到位图中,用于下一次通信。其具体代码是实现如下图所示:(左图表示由单 GPU 代码修改为 DPP 代码所需的改动;右图表示如何使用 skipping gradient synchronization。)
DataParallel Code Implementation
DataParallel (DP)
PyTorch 的 DP 实现非常简单,只需要在模型构建后使用nn.DataParallel对其进行包装(warp)即可。如下所示:

在使用 DP 包装模型后,模型的属性(例如自定义方法)变得不可访问。 这是因为 DP 中相对于原本的模型定义了一些新成员,而此时如果允许使用模型自定义属性可能会导致它们的名称和 DP 中定义的成员名称发生冲突。 如果仍然想要访问属性,解决方法是使用如下所示 DataParallel 的子类来包装模型:
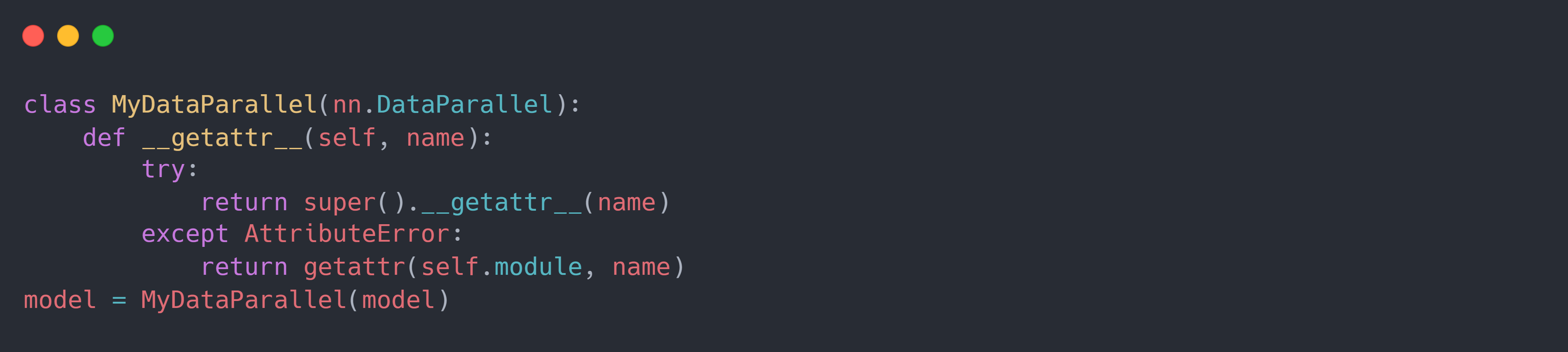
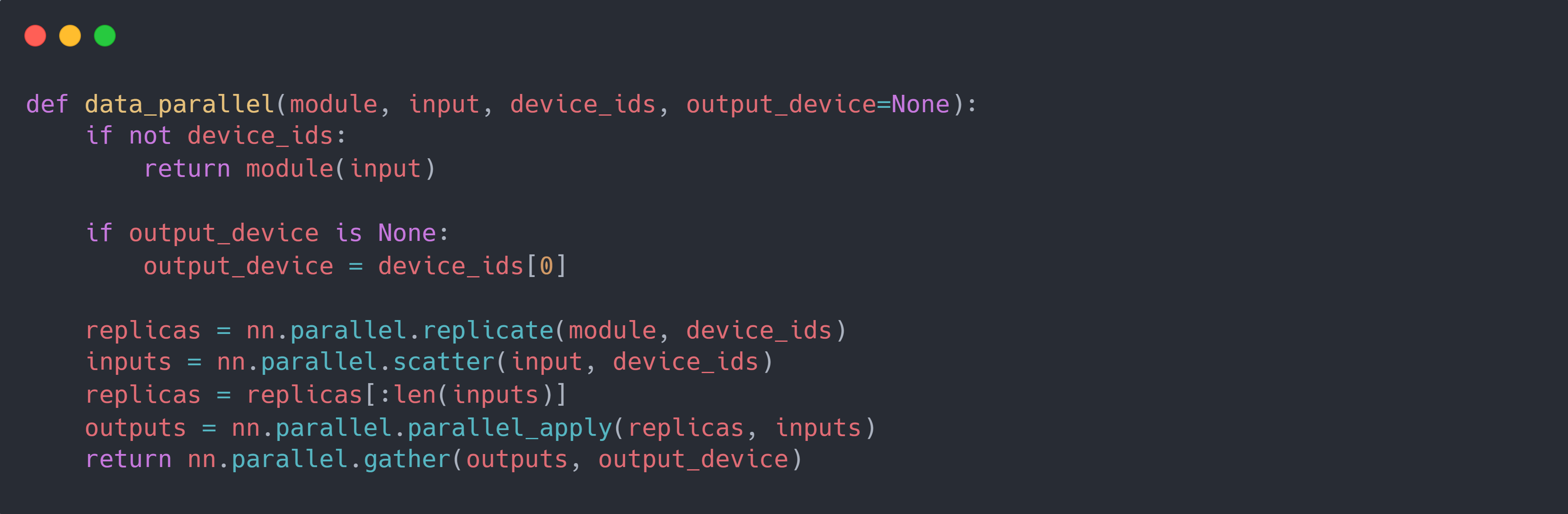
DP 模型的具体实现方式较为简单,它使用cuda:0作为通讯设备:在每次训练迭代时:
首先使用
replicate将cuda:0的模型复制到其他cuda上;然后使用
scatter将输入数据沿第一维度(batch 维度)划分到各个cuda上;接着使用
parallel_apply在各个cuda上执行模型针对给定数据的前向过程,输出各自的结果;然后使用
gather收集各个cuda上的模型输出结果到cuda:0,并将其沿第一维度进行 concat。最后,在
cuda:0上使用整个输入数据和输出结果进行反向传播计算梯度,并使用优化器针对梯度进行更新模型参数。
使用 PyTorch 自带的 MPI 语句,可以如下所示简单实现 DP:
Distributed Data Parallel (DDP)
通常而言,将每个主机称为 node;每个主机上运行的进程数称为 Local World Size (L);所有主机上运行的进程之和称为 World Size (W)。 每个进程需要 $2$ 个 IDs 来识别:一个是它在全局进程中的位置 $global\ rank \in [0, W - 1]$,另一个是它在主机内的进程中的位置 $local\ rank \in [0,L-1]$。 关于每个进程的 GPU 数,一个经验法则是一个进程对应一个 GPU。
如 Data Parallelism (DP) $\rightarrow$ Distributed Data Parallelism (DDP) 中所述,DDP 使用多个进程实现。 因此,首先需要初始化进程组:dist.init_process_group。它包括多个需要设置的参数:
backend:后端数据传输的模式,一般情况下 multi-CPU 使用gloo,multi-GPU 使用nccl;而mpi需要额外的下载配置,即 mpi 需要现在主机上配置好 mpi 通信,然后使用 PyTorch 源码包进行编译。world_size:所有节点的进程的数量之和,即进程组内的进程数量。rank:每个进程在全局进程中的位置 $\in [0, world\_size-1]$。init_method:后端的通信方式,包括使用共享文件、使用网络等。它是一个 URL 的形式,对于不同的通信方式的格式不同,其中默认的方式为 env:对于 TCP 的通信方式,其格式为
tcp://rank 0 主机的地址:端口。这种初始化方式使用rank 0作为通信主机,并且需要指定rank和world_size参数。例如:dist.init_process_group(backend, init_method='tcp://10.1.1.20:23456',rank=args.rank, world_size=4)对于 共享文件 的通信方式,它利用了文件系统,这个文件系统是共享的,并且对进程组中的所有主机都是可见的,其格式为
file://文件系统中存在的文件名/文件(不存在)。然后文件系统初始化将自动创建该文件来实现通信,但不会删除该文件。因此,需要确保在对相同的文件路径/名称进行下一次init_process_group()调用之前清理文件。同时,需要指定rank和world_size参数。例如:dist.init_process_group(backend, init_method='file:///mnt/nfs/sharedfile', world_size=4, rank=args.rank)对于环境变量(env)的通信方式,其与 TCP 的通信方式相似,都是以
rank 0作为通信主机,不过该方法是从环境变量中读取配置,从而允许完全自定义获取信息的方式。要设置的变量有:MASTER_PORT:
rank 0的可用端口,默认 $29400$;MASTER_ADDR:
rank 0的地址,默认 $localhost$;WORLD_SIZE:所有节点的进程的数量之和(也可在
init_process_group中设置);RANK:每个进程在全局进程中的位置(也可在
init_process_group中设置)。
然后需要将模型使用 DDP 进行包装(warp):ddp_model = DDP(model, device_ids=[cuda 0 ~ n]), 在 DDP 中需要指定模型所使用的 GPU device_ids,每个 GPU 在各自的主机内都是从 $0$ 开始命名。 一般而言,每个进程都使用一个 GPU,则每个模型也使用一个 GPU,这时可以使用 $local\ rank$ 来表示device_ids,即device_ids=[local_rank]。
最后,需要在每个主机上启动多进程的代码,主要包括torch.multiprocessing、torch.distributed.launch和torchrun $3$ 种启动方式。
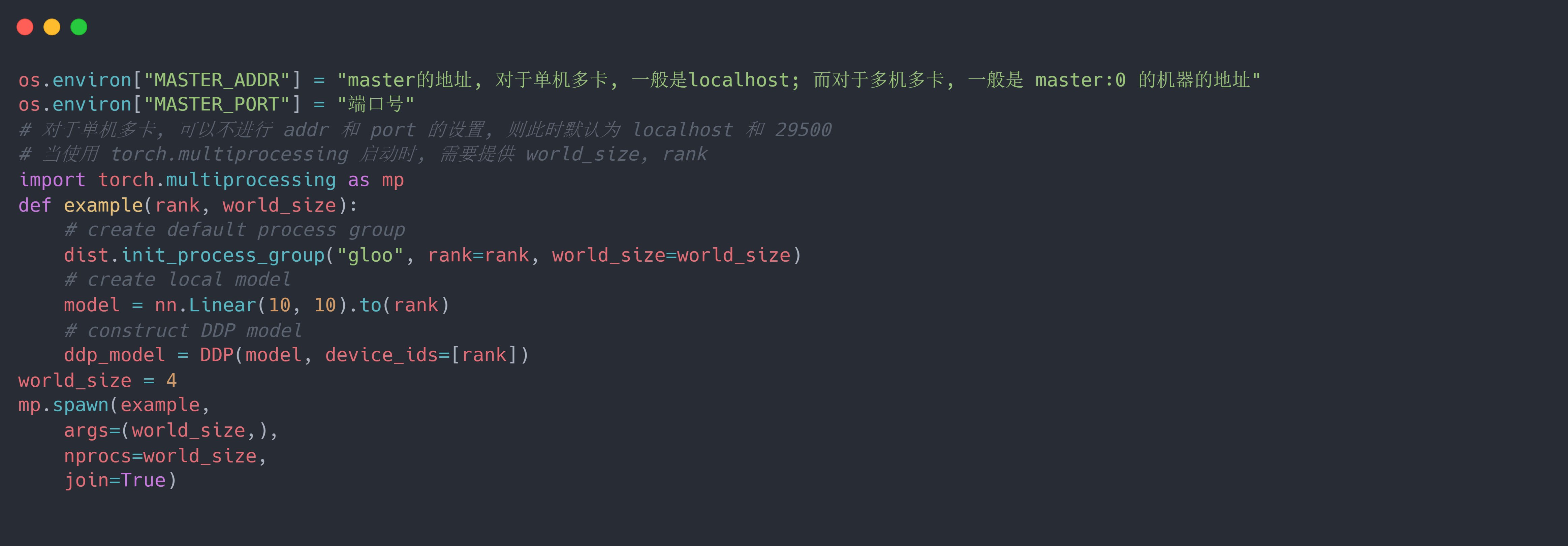
假设使用gloo后端数据传输模式,env 通信方式的初始化,则使用torch.multiprocessing启动的代码为:
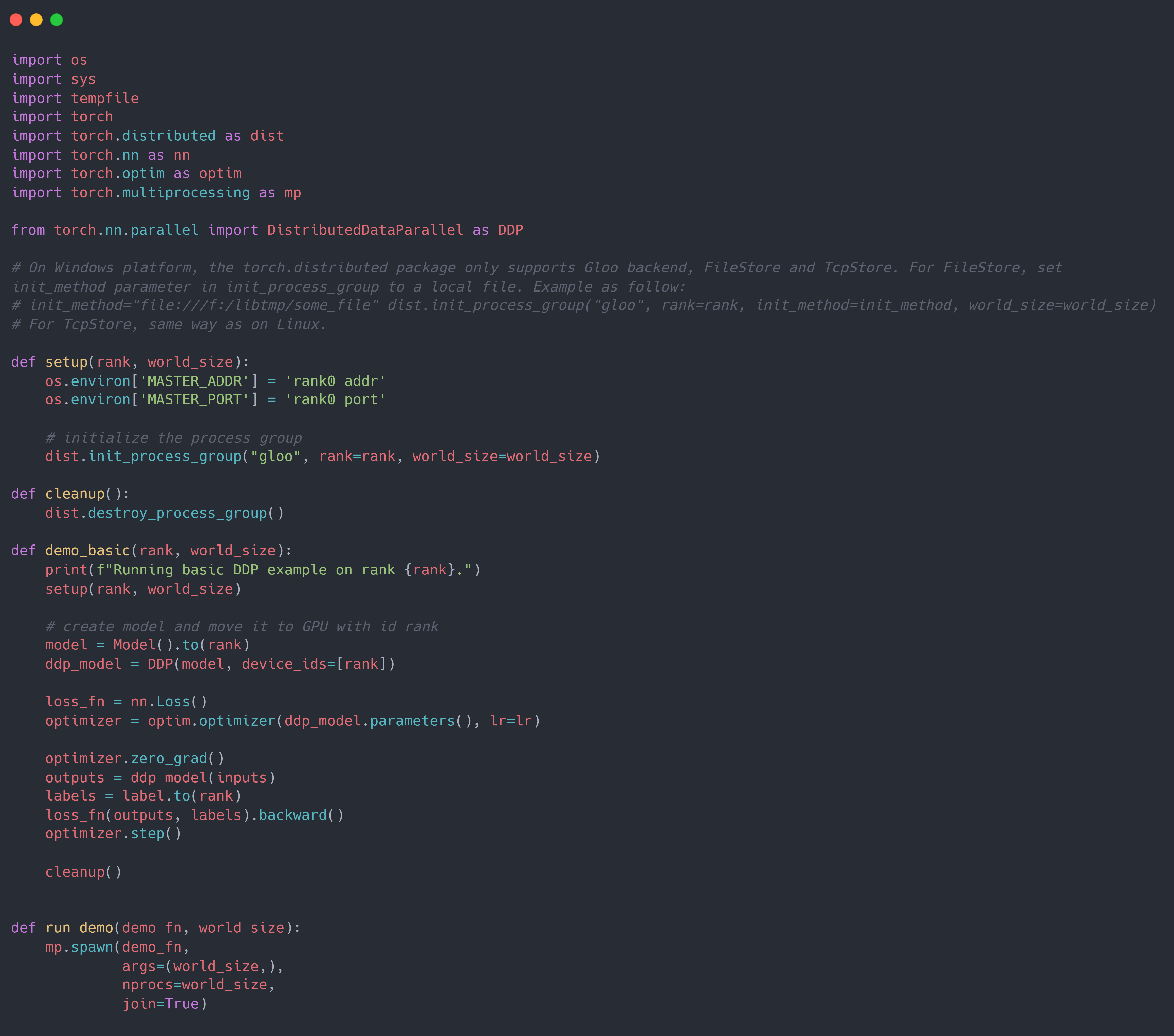
使用torch.distributed.launch启动的代码为:

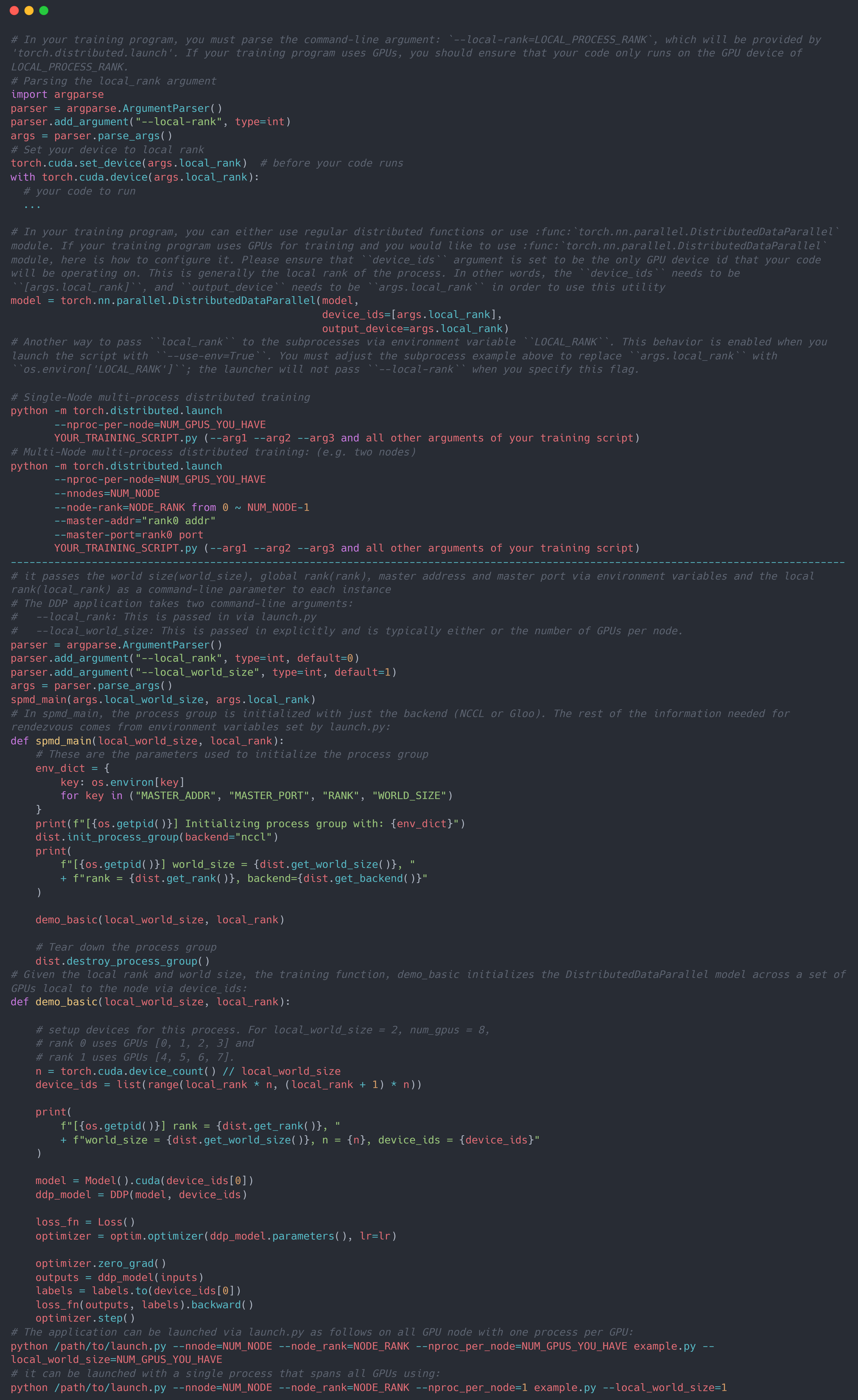
使用torchrun启动的代码为:
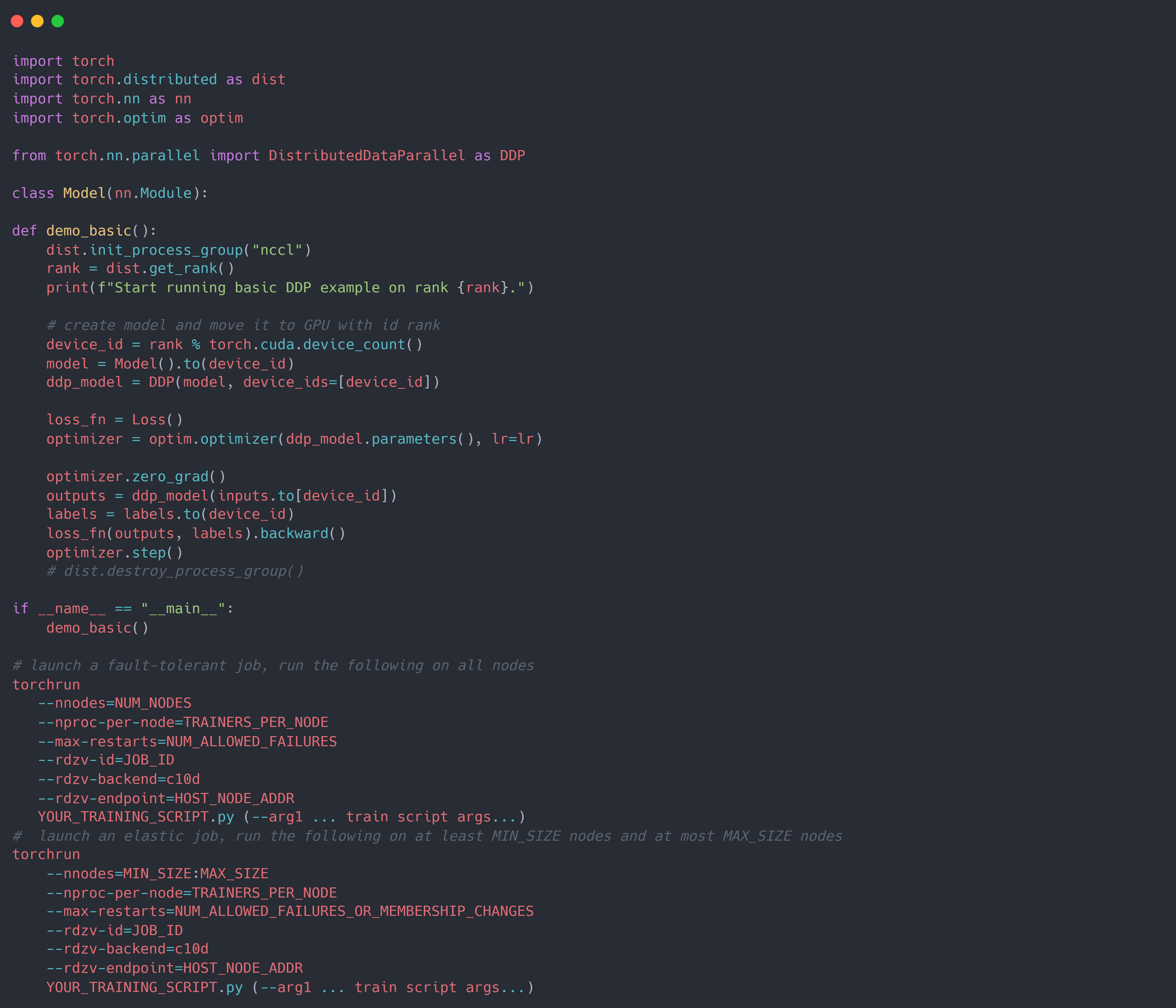
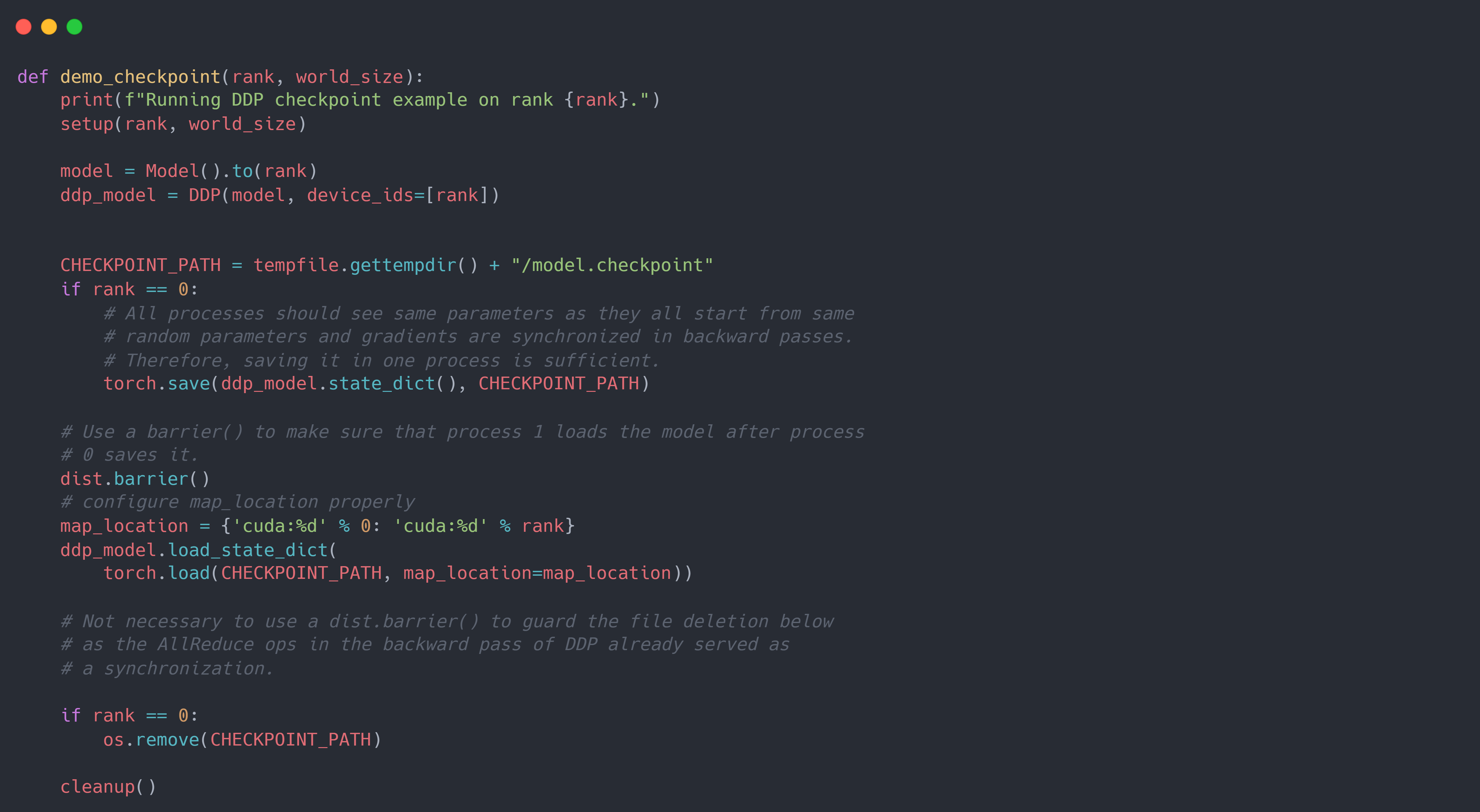
保存模型参数:当使用DDP时,一种优化是将仅保存一个进程的模型参数,然后需要使用时将其加载到所有进程中,以减少写入开销。 因为所有进程都从相同的参数开始,并且梯度在反向传递中是同步的,因此优化器应该将参数设置为相同的值,即所有进程的模型参数是一致的。 使用此方法需要确保在模型参数保存完成之前没有进程开始加载。此外,在加载模型时,需要提供适当的map_location参数,以防止进程进入其他进程的 GPU。 如果缺少map_location,则torch.load首先将模块加载到 CPU,然后将每个参数复制到保存它时的 GPU 上,这将导致同一机器上的所有进程使用同一个 GPU。
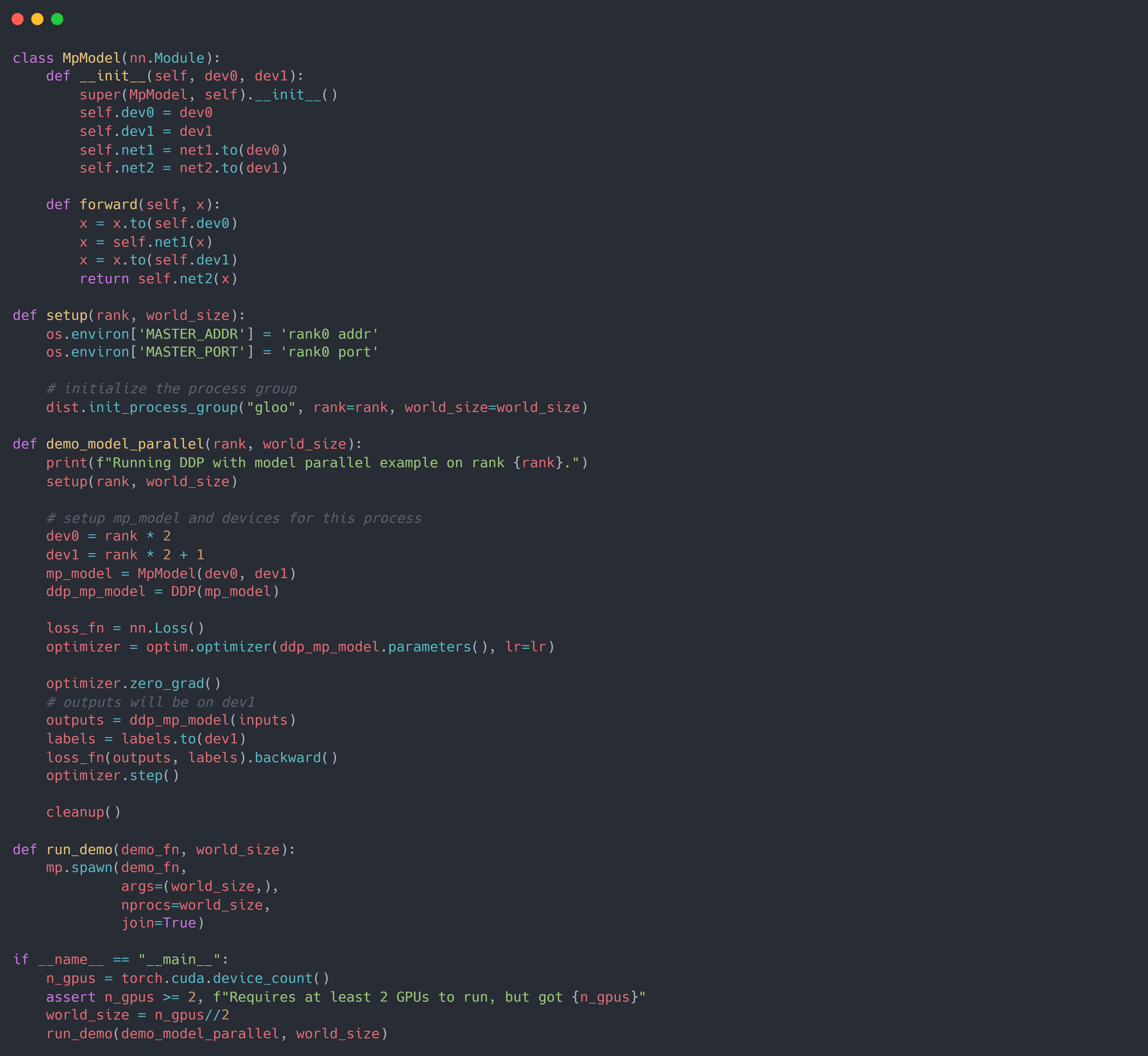
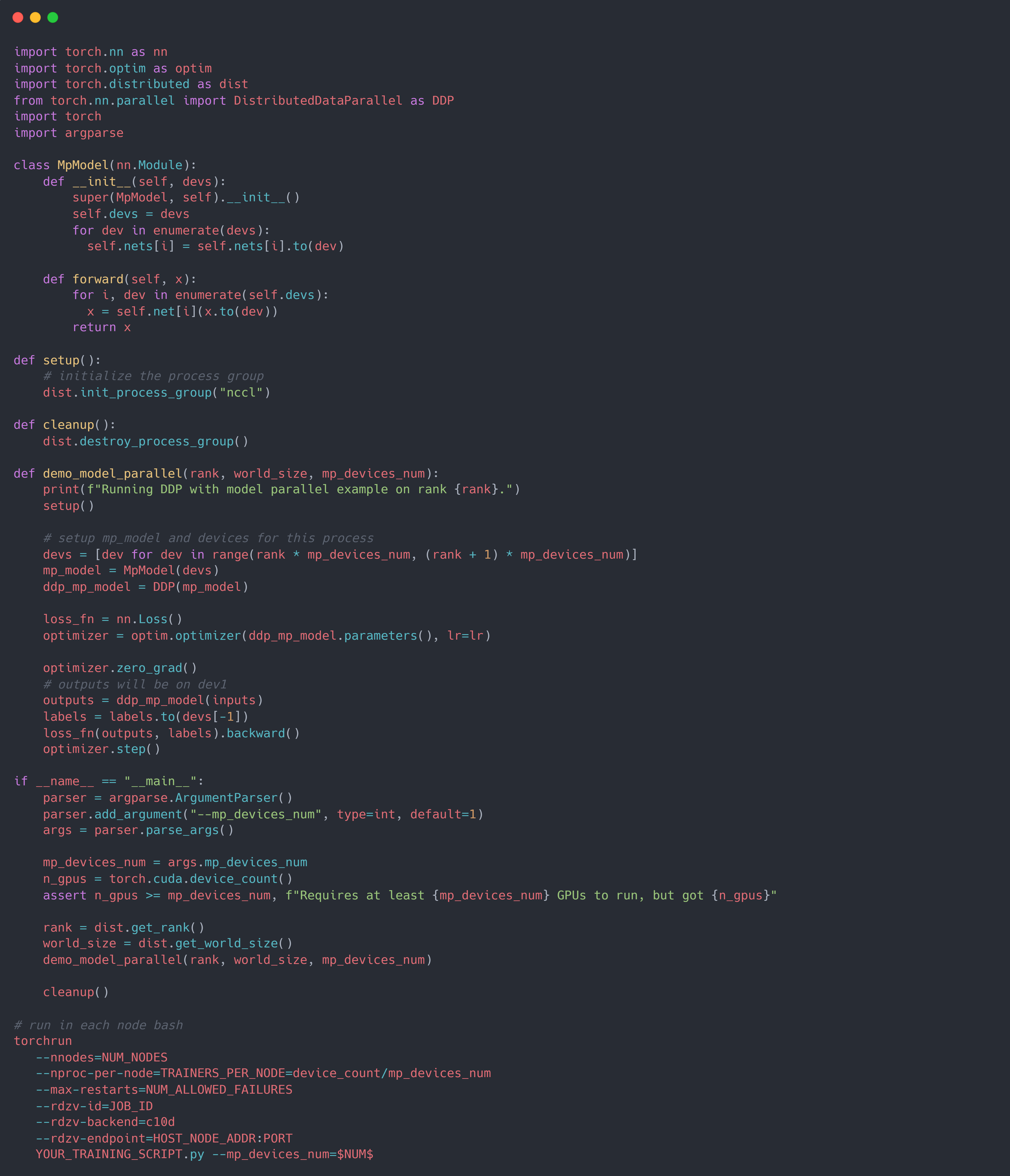
将 DDP 与 PP (Pipeline Parallel) 结合起来,即可实现更加大型的模型训练。 如下所示,假设 PP 的 GPU 数为 $2$,则world_size$=$所有 node 的 GPU 数 $/2$, 然后使用rank来标记当前的 GPU 组数,即第 $rank$ 个进程的 PP 使用的 GPU 为 $[rank, rank+1$。 需要注意的是,由于模型使用的是 PP,即 multi-device,因此DDP中的device_ids参数不能设置,只能使用默认值None; 且模型的输入数据必须显式将其设置到指定的 device 上:x=x.to(self.dev0)。
Conclusion
因此,一个 DDP + PP 的 PyTorch 实现框架如下:
Appendix
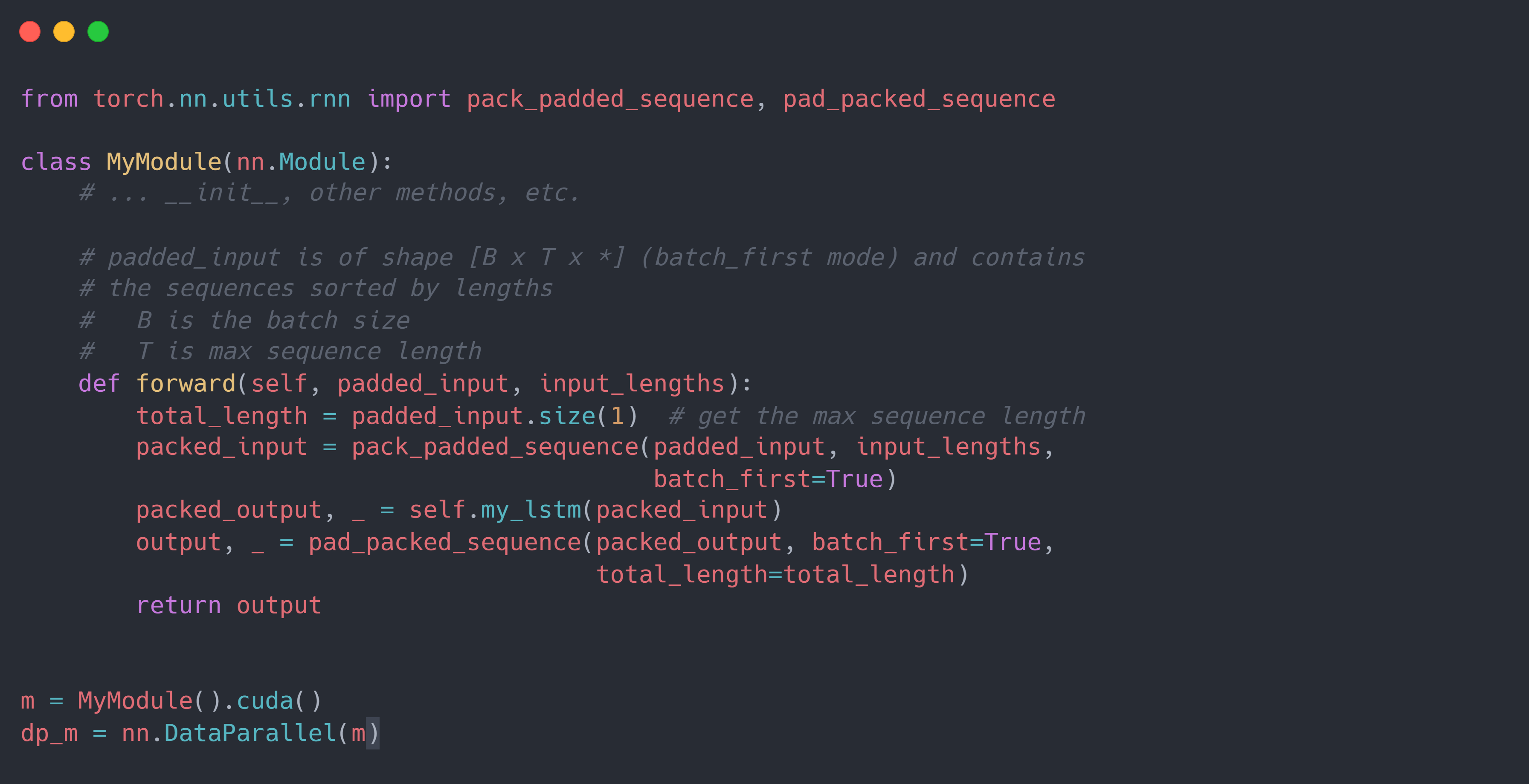
1. Data Parallelism 运用在序列数据上的差异,即在使用 DP 或 data_parallel() 的模型中使用 打包序列 $\rightarrow$ 循环网络 $\rightarrow$ 解包序列 的模式有一个不同之处:
每个设备上的forward()的输入将只是整个输入的一部分。因为解包操作torch.nn.utils.rnn.pad_packed_sequence()默认情况下只填充到它看到的最长输入,即当前设备上最长的输入(而且有可能每个设备上的最长输出的长度不一致),所以当输出结果聚集在一起时将发生长度不匹配,无法 concat。为此,可以利用pad_packed_sequence()的total_length参数来确保 forward() 调用返回相同长度的序列,如下所示:
References
- Techniques for training large neural networks
- How to Train Really Large Models on Many GPUs?
- pytorch DDP overview
- all reduce theory
- init_method 定义的 GPU 之间的通信模式
- Launching and configuring distributed data parallel applications
- distributed launch.py
- Getting Started with Distributed Data Parallel
- Distributed Data Parallel
- Writing Distributed Applications with PyTorch
- Torch Distributed Elastic
- Torch Distributed Elastic Quickstart
- Saving and Loading Models
- All_Reduce 原理
- Multi-GPU Training in PyTorch with Code (Part 3): Distributed Data Parallel
- Multi-GPU Training in PyTorch with Code (Part 4): Torchrun
- Multi node PyTorch Distributed Training Guide For People In A Hurry
- PyTorch Distributed Training
- Getting Started with PyTorch Distributed