The Basic Knowledge of Automatic Mixed Precision
Published:
这篇博客主要讲解了使用自动混合精度(AMP)降低模型内存占用的原理和具体实现。
Automatic Mixed Precision
混合精度训练(MPT)主要是指在模型训练过程中,将其中一些操作的输入输出数据使用 $float16$ 的半精度数据类型存储,无法使用的则正常使用 $float32$ 单精度数据类型存储。 而自动混合精度(AMP)则是自动地执行 MPT,即自动给每个操作的输入输出数据匹配合适的数据类型。通常而言,AMP 主要包括 $2$ 个部分:autocast 和 grad scale。
其中,autocast 即狭义上的 AMP。在一般的模型训练中,PyTorch 对数据存储都是采用 $float32$ 的单精度形式,则对于每个数据的存储都需要使用 $32$ 位的空间。 反观 $float16$,它的内存占用仅为 $float32$ 的一半,这使得在使用 $float16$ 的情况下,同等内存容量的 GPU/CPU 可以训练更大的模型、使用更大的 batch size。 同时,$float16$ 在计算上由于经过硬件优化,计算速度一般会快于 $float32$,并且由于数据存储位数减少,其在 DDP / MP 等训练时的通信量也减少,即减少等待时间,加快数据的流通和模型的训练。
但是,使用 $float16$ 存在一些问题。首先是数据溢出问题(overflow/underflow)。 由于 $float16$ 的表示范围和精度 $\ll$ $float32$,因此很可能出现数据超过其表示范围(overflow)或者小于其表示范围(underflow)。 其中后者在训练时更为常见(在训练后期模型参数的梯度很小,很有可能小于 $float16$ 的数据范围)。 其次是舍入误差(Rounding Error),在 backward 计算完成梯度后,需要进行参数更新:p = p - lr * p.grad。 此时由于参数的数量级 $\gg$ 梯度的数量级,导致在参数的数量级下的 $float16$ 最小间隔数量级增加,进而导致即使梯度大于 $float16$ 的最小表示,也会在与参数相加后被舍弃,从而导致本次参数更新失败。
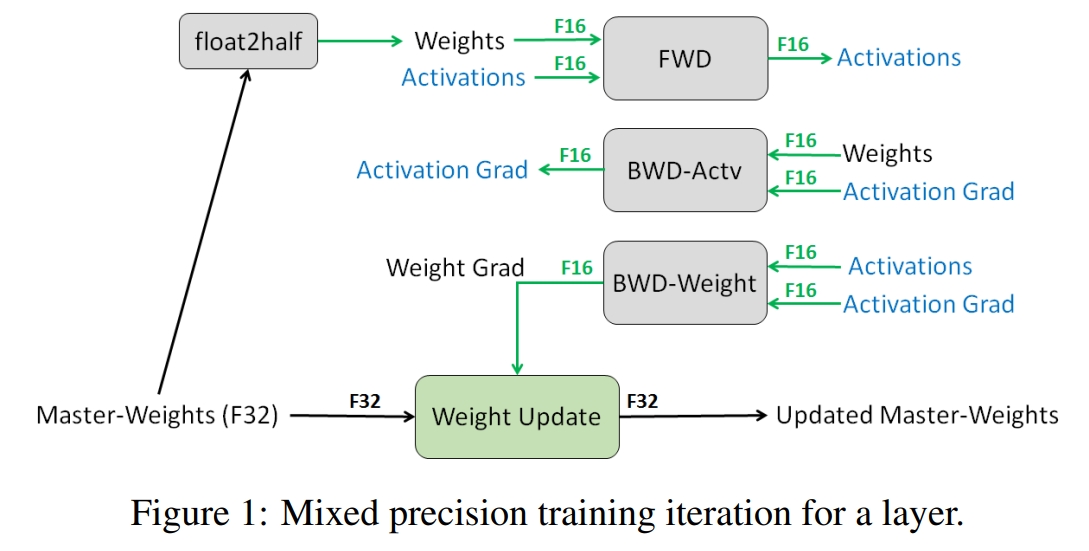
为了解决第二个问题,autocast 采用 $float16$ 和 $float32$ 数据精度混合的方式来表示不同的数据,并备份参数的 $float32$ 版本来进行参数更新。 具体而言,首先备份一份参数的 $float32$ 版本,然后在模型的 forward 过程中,权重(weights)和数据(datas)都使用 $float16$ 表示,则模型计算的中间输出结果(activations)也使用 $float16$ 表示。 而在模型的 backward 过程中,由于中间输出结果(activations)和权重(weights)都是使用 $float16$ 表示,则计算得到的各自的梯度(activation grad 和 weight grad)也是使用 $float16$。 其中 activation grad 主要是为了参与位于其后面的模型参数梯度的计算,因此只需保持 $float16$ 即可;而 weight grad 需要进行模型参数的更新。 为了防止舍入误差,需要将 weight grad 转化为 $float32$ 的数据表示以提高数据表示范围,接着与备份的参数的 $float32$ 版本进行参数更新。此时由于将数据表示都提高到了 $float32$,因此不会出现舍入误差问题。 上述的具体数据表示如下图所示,可以看到将模型的大部分数据都使用 $float16$ 进行表示,节省了大量的内存空间。
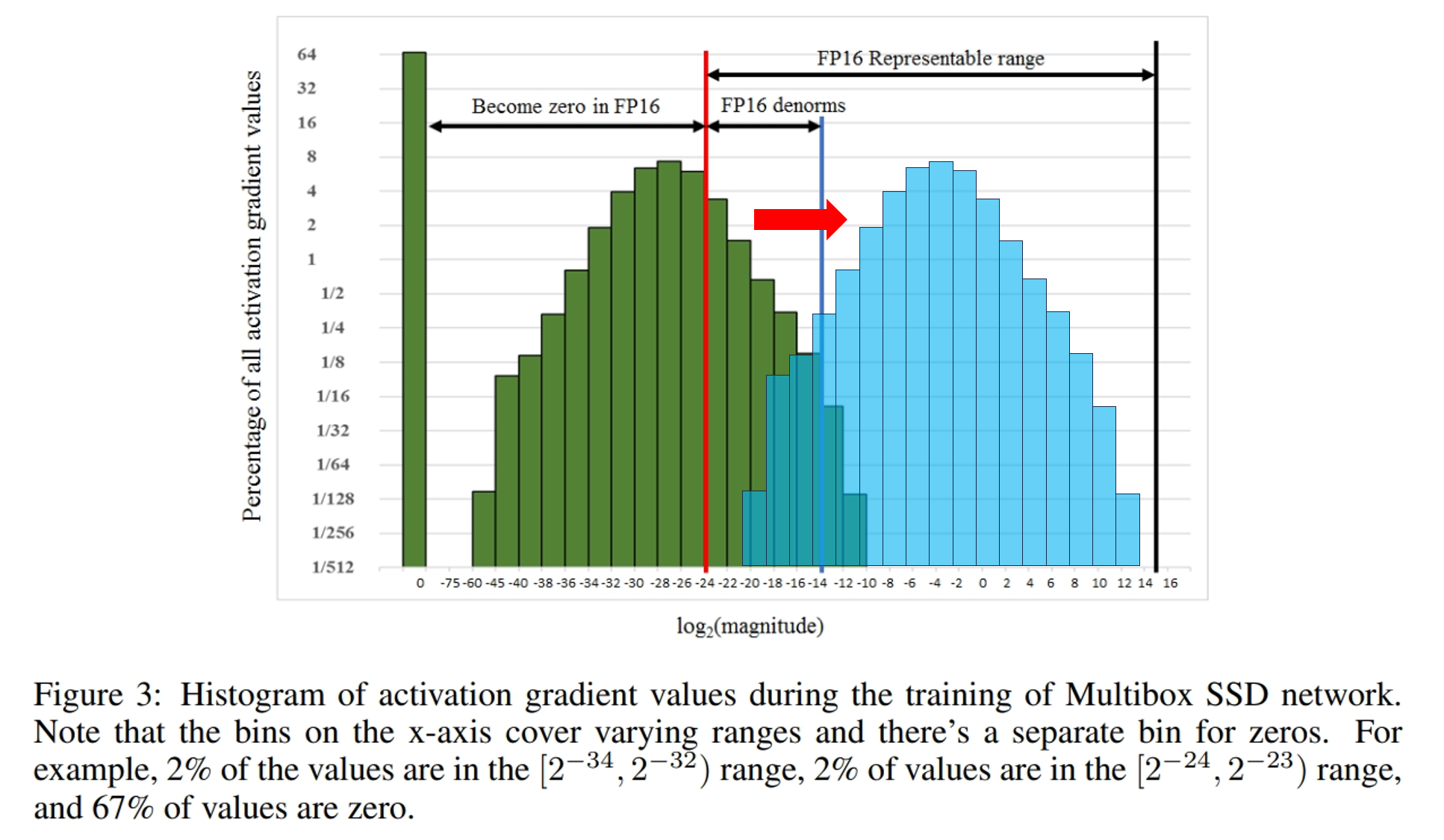
针对第一个问题,可以使用梯度缩放。仔细研究第一个问题,可以发现上溢和下溢几乎不会同时发生且绝大部分是发生下溢($float16$ 的上界为 $65504$,在模型训练时几乎不可能会有这么大的计算结果), 因为在模型训练的后期,参数的梯度普遍较小,再乘上 $<1$ 的学习率,很可能会导致下溢发生。如下图所示,在一个模型(Multibox SSD)的训练中,几乎有 $67\%$ 的数据都发生了 $float16$ 下溢, 但是它们距离 $float16$ 的上界却仍有较大距离,且一个模型的训练时其数据的大小范围分布和 $float16$ 可表示的数据范围分布相近。 因此,为了尽可能避免下溢发生且能使用 $float16$ 表示,可以将模型参数的梯度统一都乘上一个较大的数 $s$,将其移动到(一般是右移) $float16$ 可表示的数据范围。 最后在计算完成梯度,并将其转化回 $float32$ 表示后,再除以 $s$ 将数据移动回来。此时由于已经转化为 $float32$,因此不会出现下溢问题。 如下图所示,乘上 $s$ 表示将原始梯度(绿色)迁移到 $float16$ 的表示范围(蓝色)。 在具体实现上,可以对模型输出的 loss 进行缩放,即 $loss \times s$,然后再进行 backward,则此时所有的梯度都会乘上数 $s$。
PyTorch Code Implementation
PyTorch 主要使用torch.autocast和torch.cuda.amp.GradScaler来实现上述的 $2$ 个改进。 其中torch.autocast主要使用上下文管理器(context manager)/修饰器(decorator)启用选定区域的 autocast,自动为 GPU 操作选择精度,在保持精度的同时提高性能。 torch.cuda.amp.GradScaler主要使用实例化对象有助于方便地执行梯度缩放的步骤。梯度缩放通过最小化梯度的下溢提高了在使用 $float16$ 数据表示梯度下网络的收敛性。 一般代码如下:
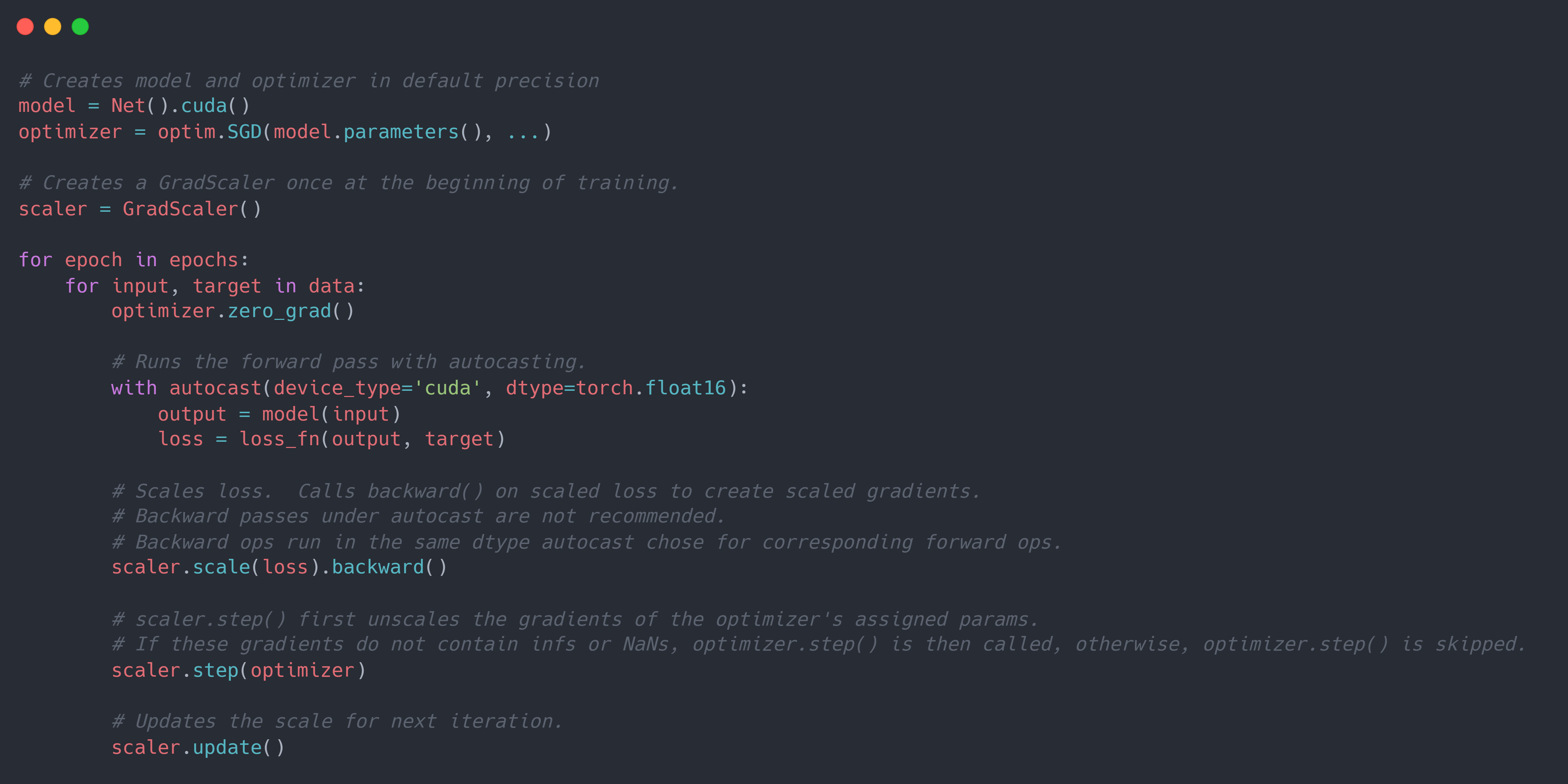
从上述代码可以看到,scaler.scale(loss).backward()产生的所有梯度都是使用 $s$ 进行缩放。 而在scaler.step(optimizer)时,会将梯度转化为 $float32$ 表示并使用 $s$ 进行逆缩放。 但是有时候,可能会在这之间对梯度进行进一步的操作(例如梯度裁剪等),由于其设置了max_norm这种与梯度有关的临界值/阈值,且为原地修改梯度。 此时就需要将梯度进行原地逆缩放。为此,可以使用scaler.unscale_(optimizer)代码进行显式地梯度逆缩放。 并且在scaler.step(optimizer)时,PyTorch 会检查代码之前是否已经调用了scaler.unscale_(optimizer)。 如果已经调用,则其不会再执行一次逆缩放过程。下面是在 AMP 的基础上添加梯度裁剪的代码:
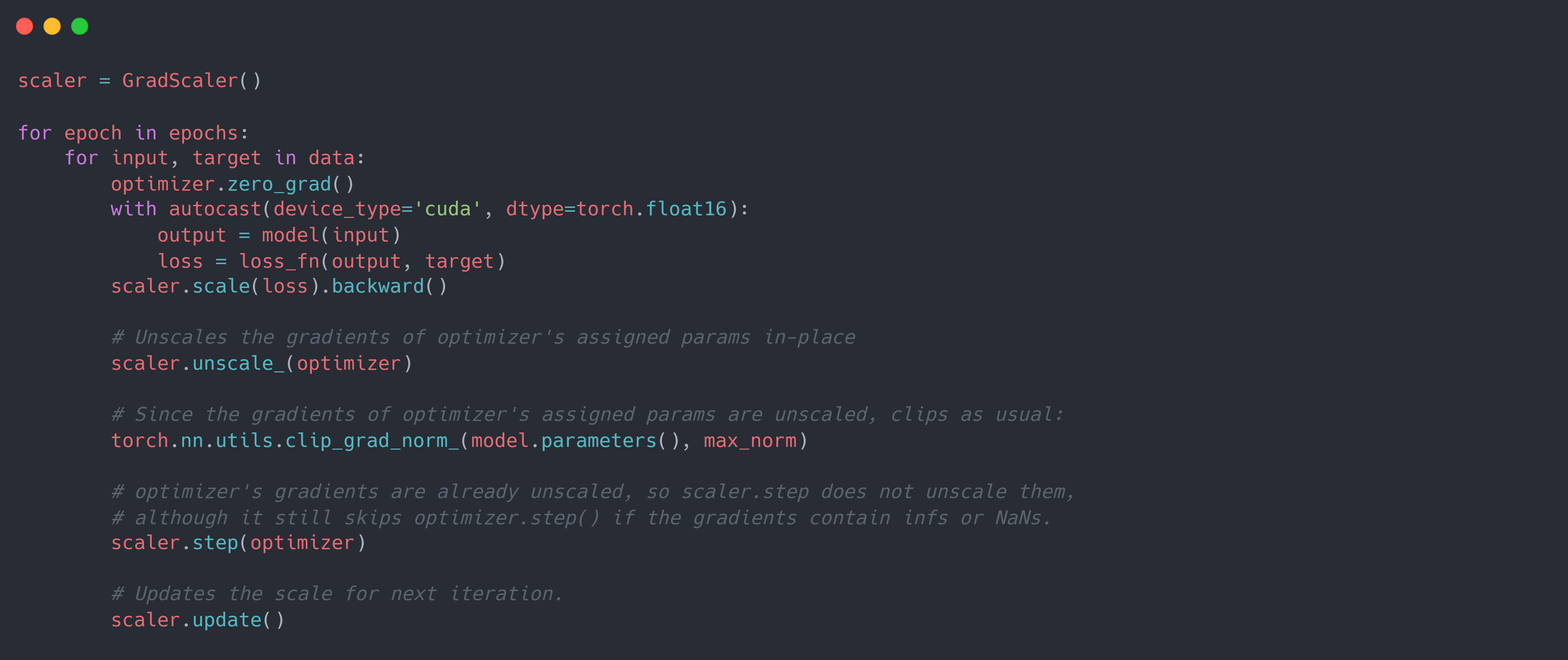
而类似于添加梯度惩罚项等的操作, 其没有设置与梯度有关的临界值/阈值,且不对原始梯度进行改变,则可以直接将梯度复制一份/再次计算一遍,并在其上进行逆缩放后操作,而原始的梯度则可以等到scaler.step(optimizer)时进行逆缩放。 下面是在 AMP 的基础上添加参数梯度惩罚项的代码:
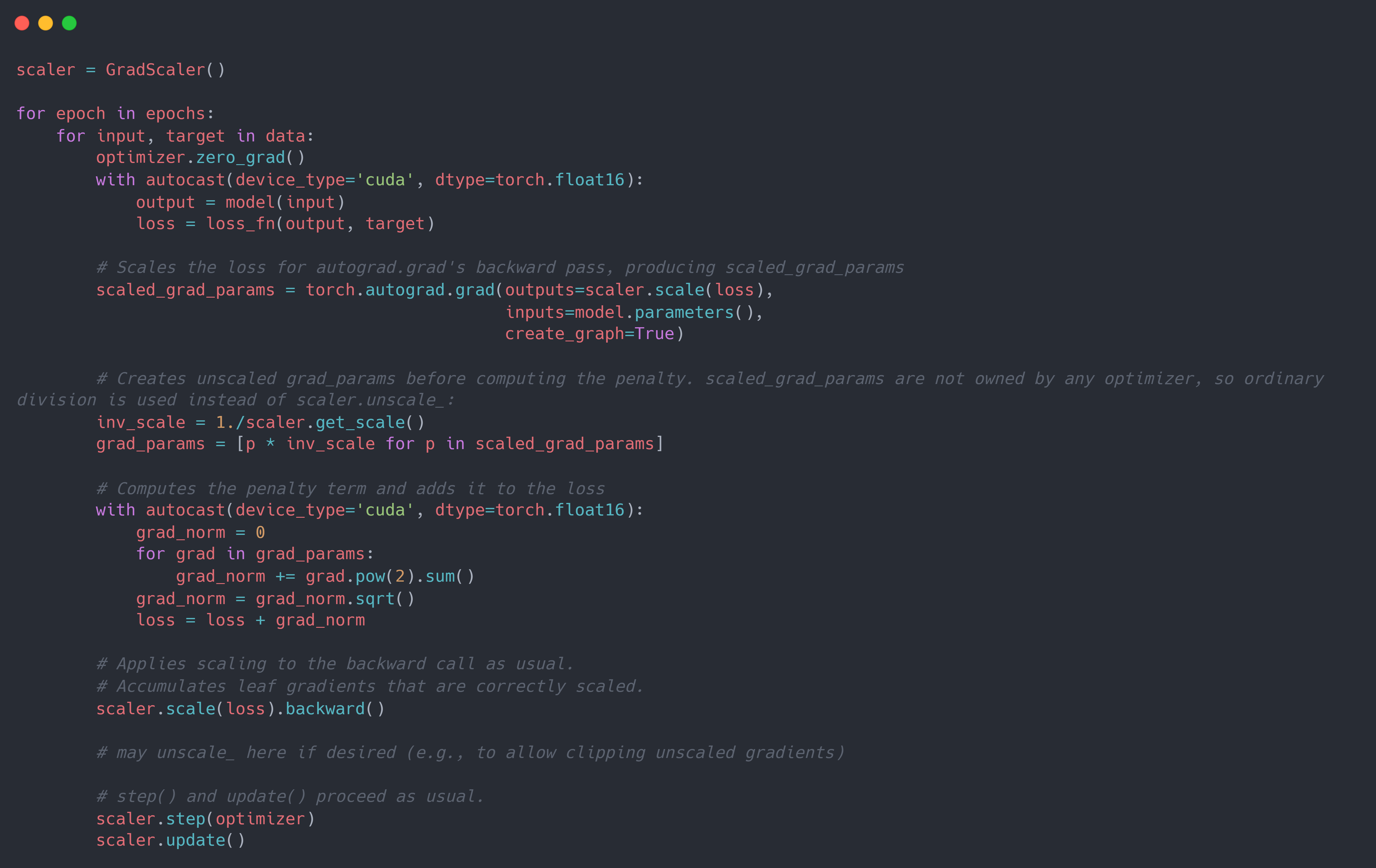
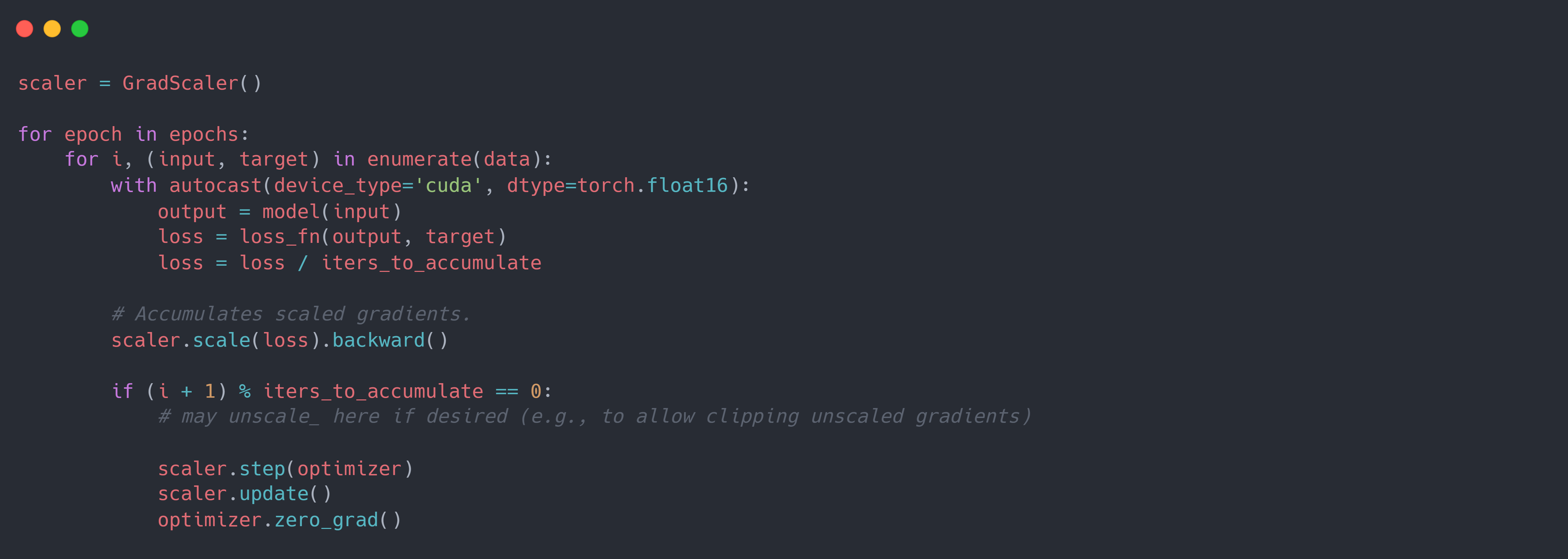
此外,在 DDP 的梯度聚合中, 由于其是多个 batch 后才收集梯度并更新参数,因此需要保证在同一个梯度聚合步骤中的梯度缩放系数一致,且梯度逆缩放必须在梯度聚合完成以后。下面是在 AMP 的基础上添加梯度聚合的代码: