The Basic Knowledge of TorchScript
Published:
这篇博客主要讲解了使用 TorchScript 将 Python 模型代码转化为其他语言代码(如 C++)的原理和具体实现。
(ps:到目前为止,我只了解了如何使用 TorchScript 将一个 PyTorch 模型转化为 TorchScript,并将其加载到 C++ 的代码中使用; 但是我并不了解 TorchScript 保存 PyTorch 模型的具体形式以及为什么 TorchScript 可以直接加载到 C++, 而传统的(说来惭愧,最近没有兴趣看关于 TorchScript 的具体原理,只能先把它的基本用法写一下。希望有所收获🤦♂, 可能未来很长一段时间都不会去继续了解 TorchScript 的具体原理)torch.save保存的 PyTorch 模型无法直接加载到 C++ 中, 其中应该和序列化方法有关联。我的计划是等我将其原理研究明白后再开始撰写这篇博客,但如果我迟迟无法理解,可能会先将 TorchScript 的具体使用先整理出来。 敬请期待⏳!)
TorchScript 是一种 PyTorch 模型的中间表示,可以简单理解为一个 PyTorch 深度学习框架的子框架。 它拥有自己的 Torch Script 模型类(即不同于一般 PyTorch 模型类 nn.Module), 并且可以使用 Torch Script 编译器对 Torch Script 模型进行理解、编译和序列化。最重要的一点是,Torch Script 模型可以在不同的语言上进行加载运行。 (这里可以类比于 Java 的 JVM,同一份 Java 代码可以在不同的操作系统上运行(Windows、Linux 等),只需要对不同的平台编写不同的 JVM 即可。 而同一份 Torch Script 模型文件也可以在不同的语言上进行加载运行(Python、C++ 等), 只需要对不同的语言编写不同的 Torch Script 操作包即可(Python 是 PyTorch 的 torch.jit,C++ 是 LibTorch)。)
这里有一个问题,即为什么需要 TorchScript 这种可以跨语言的模型格式存在? 顾名思义,PyTorch 的主要接口是 Python 编程语言。虽然对于许多需要动态性和易于迭代的场景来说,Python 是一种合适的首选语言。 但同样在许多情况下,Python 的这些属性是不利的。这些情况主要存在在生产环境中,其具有低延迟和严格部署要求。 对于生产场景,C++ 通常是首选语言,即使只是将其绑定到另一种语言,如 Java、Rust 或 Go。因此,在 Python 训练好模型后,要想部署到实际的应用场景中,通常需要使用 C++ 进行代码编写。 下面将概述 PyTorch 提供的转化方法,该方法从现有的 Python 模型转换为可完全在 C++ 中加载和执行的序列化表示,而不依赖于 Python。
第一步:需要将 PyTorch 模型转化为 Torch Script 模型。 PyTorch 提供了 $2$ 种方法可以将 PyTorch 模型转换为Torch Script。第一种是 tracing 机制,在这种机制中,模型的结构是通过使用示例输入对其进行一次 forward,并记录这些输入在模型中的流动情况来构建的。 这适用于控制流使用有限(即对if/for/while这种控制流代码的使用有限制)的模型。 第二种方法是 script 机制,通过向 PyTorch 模型中添加显式的注释(可以使用修饰器@torch.jit.script等), 通知 Torch Script 编译器它可以直接解析和编译 PyTorch 模型代码,但要受 Torch Script 语言规则的约束。
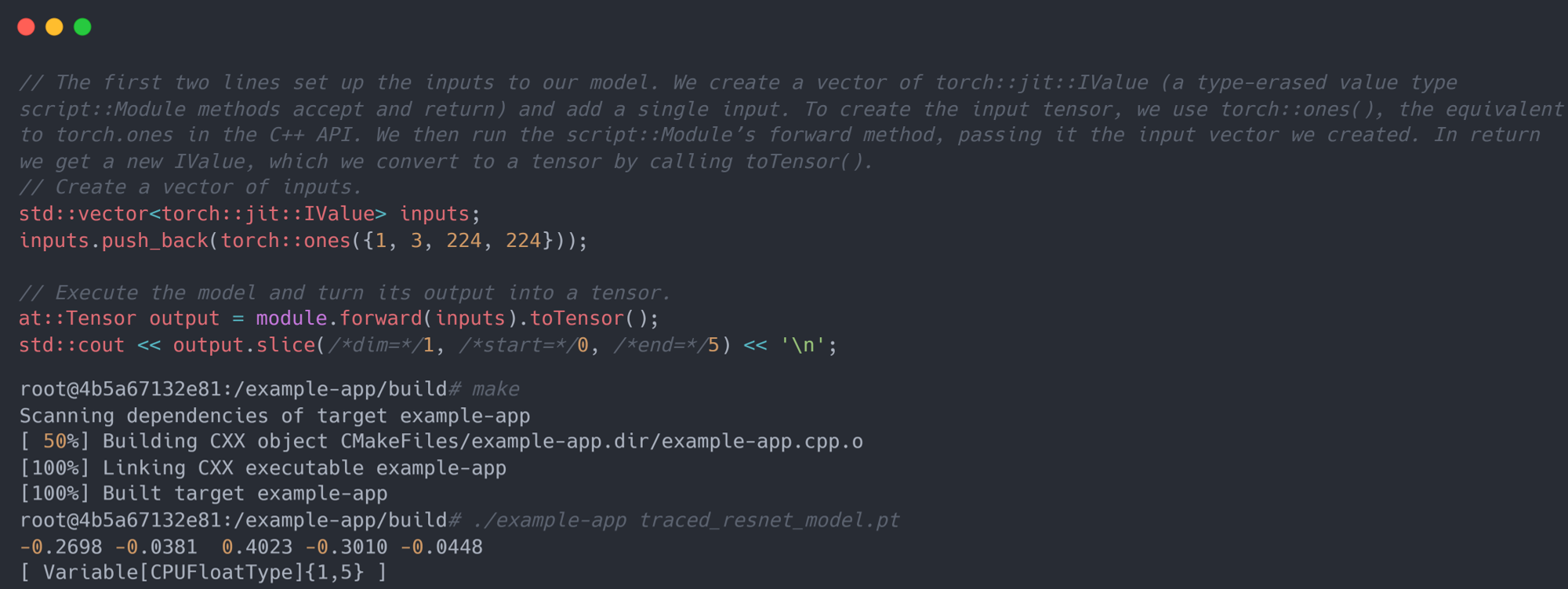
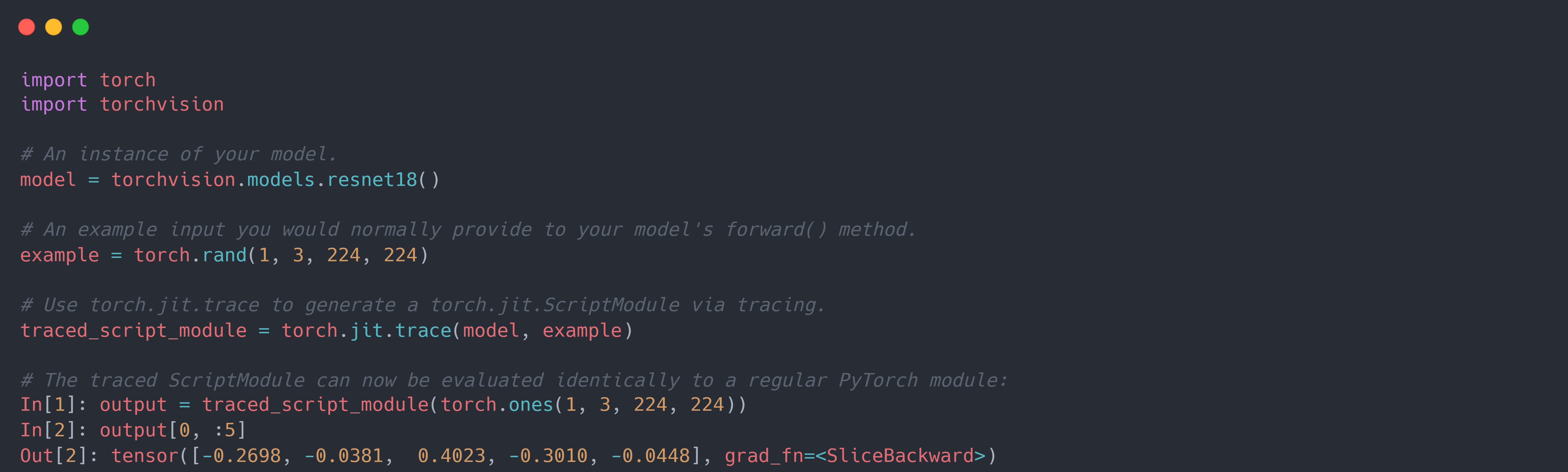
具体而言,对于 tracing 机制,必须将模型的实例以及示例输入传递给 Torch.jit.trace()函数。 它通过运行代码,追踪示例输入在模型的forward方法中的流动情况(即记录发生的操作), 并构建一个执行该操作的torch.jit.ScriptModule对象。示例代码如下:
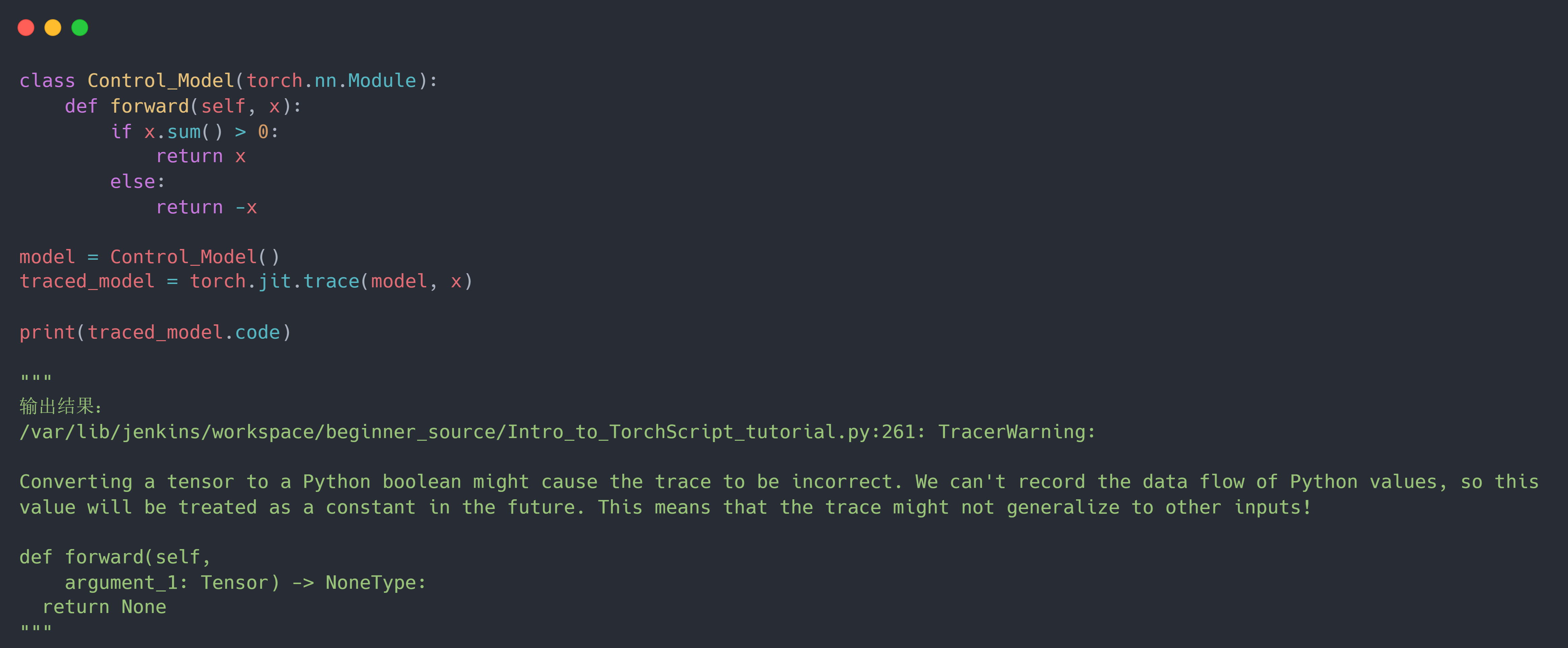
但是这种方法有个缺陷,由于它是通过追踪输入来构建模型架构,因此它无法正确转化含有控制流的模型结构。 例如对于if控制流来说,tracing 机制只会追踪到当前示例输入满足的分支,而对于另一条分支则无法追踪。在这种情况下,像控制流这样的分支操作就被简化删除了。具体错误演示代码如下:
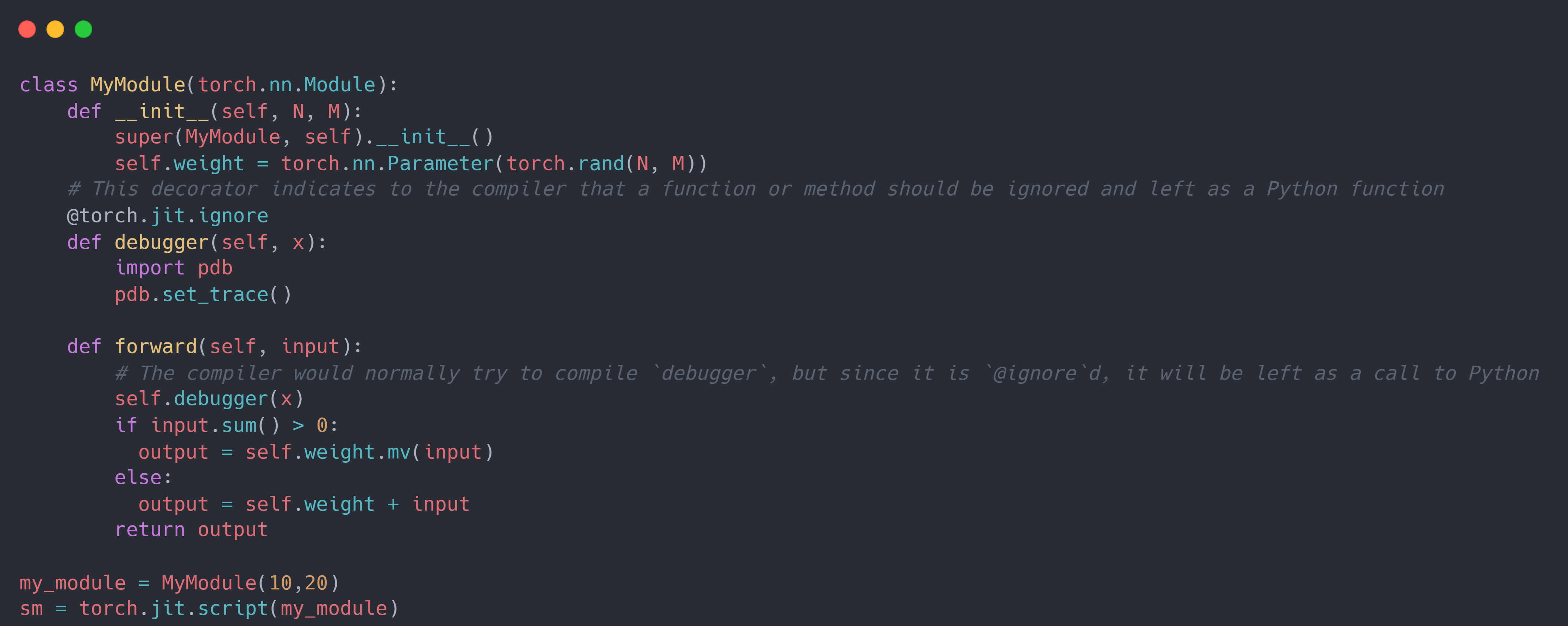
此时,就需要对模型进行直接解析,即 script 机制。具体而言,对于 script 机制, 它可以直接用 Torch Script 编写模型并相应地注释模型。首先,它需要使用修饰器来对模型的具体代码进行注释(如torch.jit.ignore)来指导 Torch Script 编译器解析模型的方式, 然后使用torch.jit.script将模型实例编译为torch.jit.ScriptModule对象。示例代码如下:
同时,这 $2$ 种方法也能嵌套使用。其中torch.jit.script可以内联torch.jit.trace模块的代码, 而torch.jit.trace也可以内联torch.jit.script的代码。
(查看 Torch Script 模型(即torch.jit.ScriptModule)的方法: 主要存在.graph和.code。 前者输出一个非常低级的表示,其中包含的大多数信息对最终用户没有用处;后者输出类似 Python 语法解释的表示。)
第二步:通过上面 $2$ 种方式可以将 PyTorch 模型实例转化为 Torch Script 模型。接下来需要将 Torch Script 模型序列化保存到硬盘中。 具体而言,一旦拥有了ScriptModule对象,就可以使用save()函数将其序列化为文件。 之后,就可以用 C++ 从这个文件中加载模型并执行它,而不依赖于 Python。 要执行此序列化,只需调用ScriptModule对象上的save()函数并传递一个文件名即可。示例代码如下:

第三步:将保存好的序列化模型加载到 C++ 代码中。 要在 C++ 中加载序列化的 Torch Script 模型,应用程序必须依赖 PyTorch 的 C++ API,也称为 LibTorch。 LibTorch 发行版包含了一组共享库、头文件和 CMake 构建配置文件(ps:虽然 CMake 不是依赖 LibTorch 的必要条件,但它是推荐的方法,并且在未来会得到很好的支持)。 下面将使用 CMake 和 LibTorch 构建一个最小的 C++ 应用程序,简单地加载和执行序列化的 Torch Script 模型。 首先,需要引入torch/script.h头文件,它包含了运行 Torch Script 模型所需的 LibTorch 库中的所有相关函数、类型、方法等。 然后使用torch::jit::load()函数反序列化该模块,该函数接受序列化后的 Torch Script Module 的文件路径作为其唯一的命令行参数, 并将该文件路径作为输入。返回结果是一个torch::jit::script::Module对象。示例代码如下:
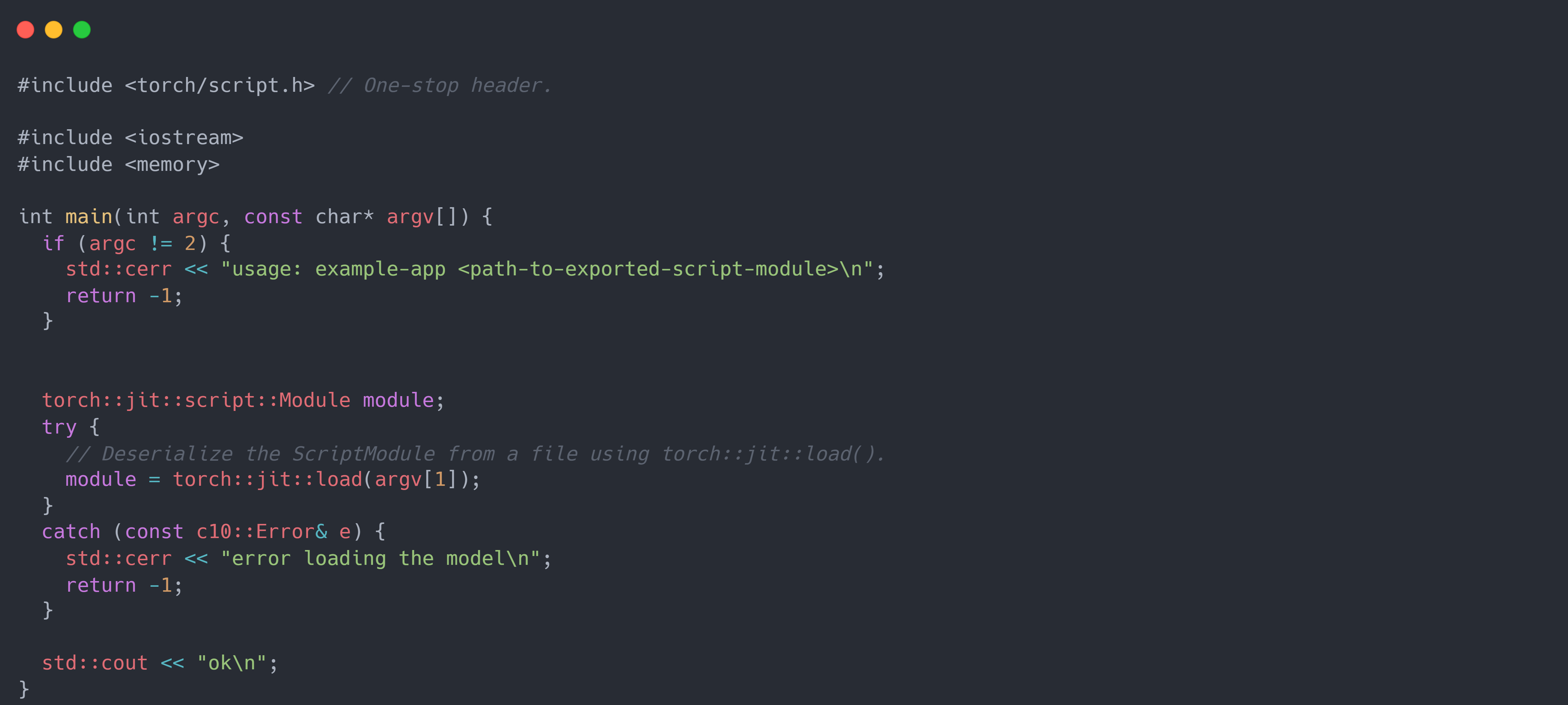
接着,使用 LibTorch 和 CMake 工具编译程序。假设将上面的代码存储在一个名为 example-app.cpp 的文件中。一个最小的 CMakeLists.txt 文件可以像下面这样简单地构建:

同时需要下载 LibTorch 发行版文件包。在下载并解压了最新的 LibTorch 存档文件后,会得到一个目录结构如下的文件夹:

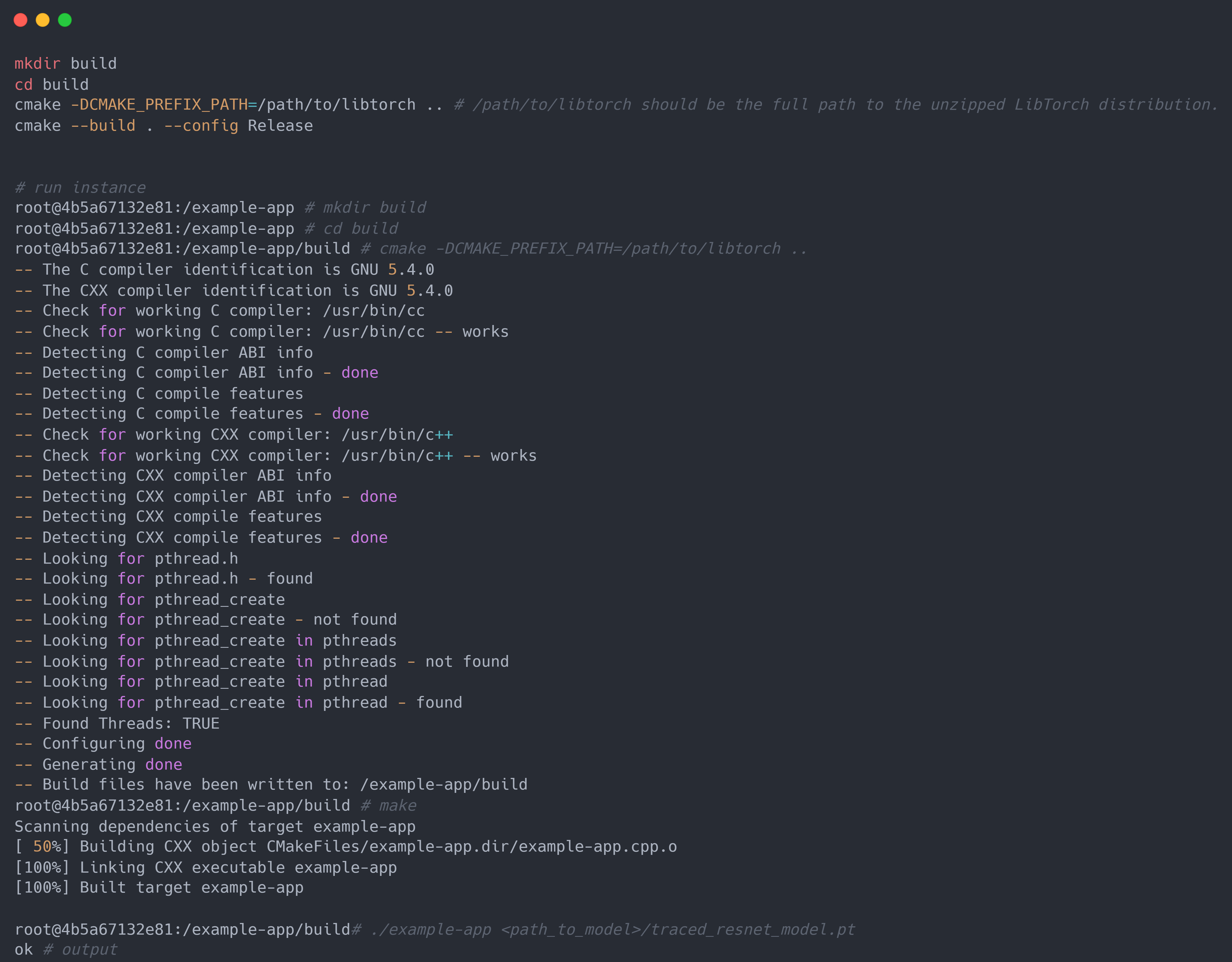
最后一步是编译代码。为此,假设给定示例文件目录如下:
example-app/ CMakeLists.txt example-app.cpp
则可以使用 CMake 编译工具对源代码进行编译。在编译完成后, 将之前保存的 ResNet18 模型traced_resnet_model.pt的文件路径提供给生成的示例应用程序二进制文件, 将会得到一个友好的 “ok” 输出(请注意,如果尝试使用my_module_model.pt运行这个例子,将得到一个错误, 说输入是一个不兼容的形状。my_module_model.pt期望的是 1D 而不是 4D)。实例代码如下:
第四步:在 C++ 代码中执行加载的 Torch Script 模型。在 C++ 中成功加载了序列化的模型之后, LibTorch 提供了很多与 PyTorch 相似的函数和方法来帮助执行模型(例如C++ 中的torch::ones对应 Python 中的torch.ones)。 示例代码如下:(ps:要将模型移动到 GPU 内存上,可以使用model.To(at::kCUDA);, 并通过调用tensor.to(at::kCUDA)来确保模型的输入也存在于 CUDA 内存中,这将在 CUDA 内存中返回一个新的张量)