
The Basic Knowledge of RLHF Training Pipeline
Update:
Published:
这篇博客主要讲解 RLHF 具体训练的框架 (DeepSpeedChat,OpenRLHF,verl) 的具体细节,包括每个框架的整体架构,架构内的各部分细节 (包括逻辑细节和代码细节)。(建议先阅读我之前关于 RLHF 的博客 The Basic Knowledge of RLHF (Reinforce Learning with Human Feedback))
RLHF 的算法流程
在之前的博客中,我们讲解了 RLHF 的三个阶段:SFT (预训练 LLM 模型 $M_\theta$),Reward Modeling (预训练奖励模型 $r_\theta$) 和最后的 RL 训练 (使用 PPO 微调 $M_\theta$)。对于前两个阶段而言,其只存在一个模型,因此可以使用 Deepspeed,FSDP,Megatron,甚至是 Transformers 的内置 Trainer 等单模型训练框架直接进行分布式训练 (关于单模型训练框架,可以参考我之后的博客)。对于第三个阶段而言,其包含多个模型,同时不同模型的作用也不尽相同 (例如,reference model 和 reward model 只用于 infer,policy model 和 value model 用于 train,同时 policy model 还用于 rollout)。因此,需要在 Deepspeed/FSDP/Megatron 这种单模型的训练框架上再进行进一步的搭建以构建多模型训练框架。因此,本文的所有 RLHF 框架其实主要是聚焦于构建第三阶段的多模型训练框架。在下面的讲解中,我将按照目前主流的描述将 policy model 称为 actor model,将 value model 称为 critic model,将 reference model 简称为 ref model。
题外话:infer 指的是使用 model 进行一次的 forward,例如使用 reward model 输入 prompt + response 只用一次 forward 就能得到 reward;train 指的是 model 还需要进行训练;rollout 指的是 model 需要根据给定的 prompt 进行多次 forward 来生成 response,即 LLM generate。由于 train 和 rollout 的不同,目前大家分别为它们构建了不同的框架,如 train 有 Deepspeed/FSDP/Megatron 等训练引擎,其计算精度较高,但是由于增加额外通信等问题导致速度较慢,主打一个如何增加较少的额外计算/通信使得 model 可以训练,即以时间换空间 (flash attention 除外);rollout 有 vllm/sglang 等推理引擎,其速度较快,但是计算损失较大,主要通过 kv cache,融合算子等操作来减少计算时间,即以空间换时间。而对于 infer,由于训练引擎和推理引擎都可以胜任,一般为了保证计算精度会使用训练引擎 (可以参考这篇博客的分析)。
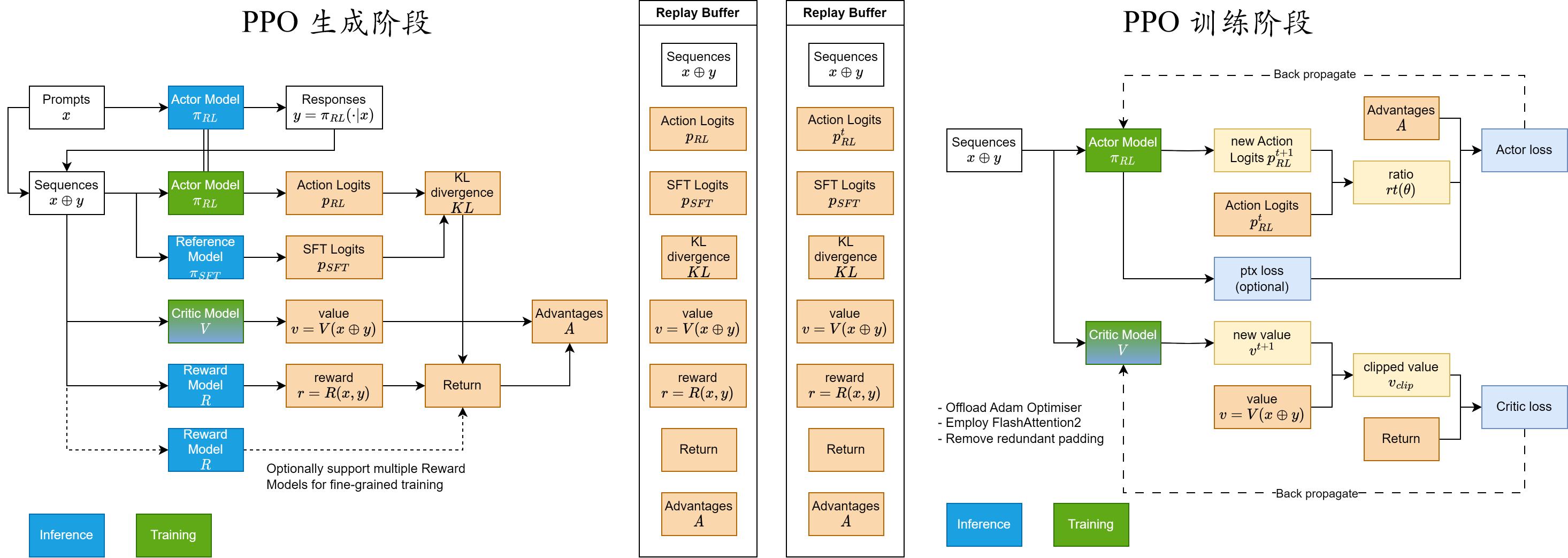
下面,我们以 PPO 为例来了解每个框架的整体架构和每个部分的具体模块 (其他的 RL 算法如 GRPO,REINFORCE++ 等基本上都是在 PPO 的基础上减少某些模块)。首先,如图 1 所示,我们先逻辑化整理一下 PPO 的算法流程:

A. PPO 的生成阶段:即通过给定的输入 prompt,生成一系列 PPO 所训练的必要的元素,在经典 RL 中也被称作环境交互。
1. 给定 SFT 后的 model,将其复制为 ref model $\pi_{SFT}$ 和需要进一步训练的 actor model $\pi_{RL}$;给定 Reward Modeling 后的 model,将其复制为 reward model $R$ 和 critic model $V$。
2. 给定 prompt $x$,将其输入给 actor model $\pi_{RL}$ 生成对应的 response $y$,得到完整的 sequence $x + y$。($\pi_{RL}$ rollout)
3. 给定 sequence $x + y$,将其输入给 actor model $\pi_{RL}$ 和 ref model $\pi_{SFT}$ 分别生成 action logits $p_{RL}$ 和 sft logits $p_{SFT}$,并进一步计算 KL divergence $KL$。($\pi_{RL}$ 和 $\pi_{SFT}$ infer)
4. 给定 sequence $x + y$,将其输入给 reward model $R$ 和 critic model $V$ 分别生成 reward $r$ 和 value $v$。($R$ 和 $V$ infer)
5. 给定 $KL$ 和 $r$,计算得到 PPO 的 return;并通过给定 $v$,计算得到 PPO 的 advantage $A$。
B. PPO 的训练阶段:即通过 PPO 的生成阶段所得到的元素,进行 PPO 的训练,在经典 RL 中也被称作奖励学习。由于 PPO 的生成阶段的时间成本较高,因此通常对生成阶段得到的元素进行缓存,并进行多次训练。对于第 $t$ 次训练,其具体流程如下:
1. 给定 sequence $x + y$,将其输入给第 $t-1$ 次训练完的 actor model $\pi^t_{RL}$ 生成 new action logits $p^{t}_{RL}$,并和 action logits $p_{RL}$ 计算 ratio $r^{t}(\theta)$。接着和给定的 advantage $A$ 计算 actor loss 用于 actor model 的训练。($\pi_{RL}$ train)
2. 给定 sequence $x + y$,将其输入给第 $t-1$ 次训练完的 critic model $V^t$ 生成 new value $v^{t}$,并和 value $v$ 计算 clipped value $v_{clip}$。接着和给定的 return 计算 critic loss 用于 critic model 的训练。($V$ train)
题外话:通过上述的步骤不难发现需要在 PPO 生成阶段缓存的元素 (用于 PPO 训练阶段的多次训练) 包括:生成的 sequence $x + y$,action logits $p_{RL}$,value $v$,advantage $A$ 以及 return;但是为了避免后续算法有额外的需求,一般会将 sft logits $p_{SFT}$,KL divergence $KL$ 以及 reward $r$ 一起缓存。
DeepSpeedChat
可以看到,上述的流程涉及到 actor model $\pi_{RL}$ 的 rollout,actor model $\pi_{RL}$ 和 ref model $\pi_{SFT}$ 的 infer,reward model $R$ 和 critic model $V$ 的 infer,以及 actor model $\pi_{RL}$ 和 critic model $V$ 的 train。最直接的实现方式是,按照上述流程的逻辑编写 PPO 训练的架构,通过简单扩展单模型训练框架得到多模型训练框架。如图 2 所示,DeepSpeedChat 就是按照这种思路扩展 DeepSpeed 框架来实现 PPO 的训练的。(下面讲解的 DeepSpeedChat 的版本为 bd47e5bc38d292f44bf183e7bda992cde36a769b)

接下来,我们讲解 DeepSpeedChat 的每个模块的逻辑和代码细节:
与之后的博客中讲解的 DeepSpeed 的分布式训练一致,DeepSpeedChat 通过 deepspeed 命令启动分布式训练,并在每张卡上运行 main.py 文件。
1. 第一阶段:在 main.py 文件中,首先是使用 deepspeed.init_distributed() 初始化分布式环境,load_hf_tokenizer() 加载 tokenizer,create_datasets() 加载数据集。接着,初始化 DeepSpeedRLHFEngine,包括初始化 actor model,ref model,reward model 和 value model,其中 actor model 和 critic model 是通过 get_train_ds_config() 获取 train 的 config 实现 DeepSpeedEngine 的初始化,而 ref model 和 critic model 是通过 get_eval_ds_config() 获取 infer 的 config 实现 DeepSpeedEngine 的初始化。具体而言,以 actor model 初始化为例,其是调用 DeepSpeedRLHFEngine 的 _init_actor() 方法,该方法主要包括通过 get_train_ds_config() 来获取 ds_config;通过 create_hf_model() 来加载 HF 格式的 actor_model;构建 optimizer 和 lr scheduler;最后使用 deepspeed.initialize() 将三者封装为 DeepSpeedEngine。然后,初始化 ppo_trainer,这是一个 DeepSpeedPPOTrainer 训练类,里面包含了所有关于 PPO 计算模块的函数。其初始化的过程就是简单的对 PPO 所需的各个 model 和系数等进行赋值。最后,初始化 exp_mini_dataset,其是一个 MiniDataset 类,用于缓存后续 PPO 生成阶段的结果,并提供给 PPO 训练阶段使用。
2. 第二阶段:在完成初始化和数据的准备后,下一步便开始 PPO 的生成和训练阶段。PPO 的生成阶段 主要由 DeepSpeedPPOTrainer.generate_experience() 实现:通过给定准备好的 prompt,首先使用 DeepSpeedPPOTrainer._generate_sequence() 来生成 response,其内部调用了最原始的 model.generate() 的方式。接着,将生成好的 sequence (prompt + response) 输入给 actor model 生成 $p_{RL}$,输入给 ref model 生成 $p_{SFT}$,输入给 reward model 生成 $r$,最后输入给 critic model 生成 $v$,最终将生成的所有结果通过 add() 缓存到 MiniDataset 中。
3. 第三阶段:完成 PPO 的生成阶段,便是 PPO 的训练阶段,其主要是通过 DeepSpeedPPOTrainer.train_rlhf() 实现。可以发现,为了更好地利用 PPO 生成阶段所生成的结果,一般会使用其进行多次训练,对应代码中的 args.ppo_epochs。对于第 $t$ 次训练,首先是根据 PPO 生成阶段的 $p_{RL}$,$p_{SFT}$ 和 $r$ 使用 compute_rewards() 计算 old_rewards (这里可能会有些奇怪,在上述的 RLHF 的算法流程中似乎没有这个流程,其实这里就是计算 $KL$,并将其融入到 $r$ 中进行后续的计算而已)。接着便是通过 get_advantages_and_returns() 使用标准的 GAE 生成 $A$ 和 return。对于 actor model,接着计算 $p^t_{RL}$,并和 $p_{RL}$ 计算 $r^t(\theta)$ (这里需要注意,因为 actor model 已经经过了 $t-1$ 次的更新,因此计算得到的 $p^t_{RL}$ 和 $p_{RL}$ 不相等,如果 args.ppo_epochs 等于 $1$,那么其二者会一直相等,即 $r^t(\theta)$ 恒等于 $1$)。最后通过 actor_loss_fn() 计算 actor loss,并进行 backward 和 actor model 参数更新。而对于 critic model,接着计算 $v^t$,并和 $v$ 计算 $v_{clip}$ (这里需要注意,因为 critic model 也已经经过了 $t-1$ 次的更新,因此计算得到的 $v^t$ 和 $v$ 不相等)。最后通过 critic_loss_fn() 和 return 计算 critic loss,并进行 backward 和 critic model 参数更新。
总结:DeepSpeedChat 使用 deepspeed 作为所有 model 的分布式进程组的“类” (OpenRLHF 和 verl 专门定义了 *Group 类),所有 model 使用一个分布式进程组,每个分布式进程的所有 model 使用 DeepSpeedEngine 进行封装。通过将所有 model 放置在相同的 GPU 资源上,同时按照 PPO 逻辑顺序编写代码实现类似 single controller 的代码模式 (single controller 的解释参考下文)。
至此,DeepSpeedChat 的逻辑和代码细节便已讲解完毕。可以发现,DeepSpeedChat 的 PPO 训练框架的构建和上述的 PPO 的算法流程的逻辑是一致的,因此,DeepSpeedChat 的 PPO 训练框架的构建是相对容易的。同时,其将所有 model 都分配到了相同的设备上,即共用相同的 GPU 资源,如图 3 所示。这种做法的好处是可以简化代码,但是其缺点是无法实现不同 model 的并行计算,即每类 model 只能顺序执行计算,如只能 actor model infer 完后再进行 ref model infer,即便它们没有数据依赖关系。其次,对于每个 model 的不同阶段,其所需要的分布式优化不同,例如 actor model 在 rollout 时可能需要 vllm 的分布式优化,而在 train 时需要 DeepSpeed 的分布式优化。而 DeepSpeedChat 统一使用 DeepSpeed (虽然其存在 HybridEngine),导致在 rollout 时 GPU 资源利用率不高。这对于单机多卡而言,由于卡间通信较快,其可以一定程度上缓解,但是对于多机多卡而言,其资源利用率会非常低。
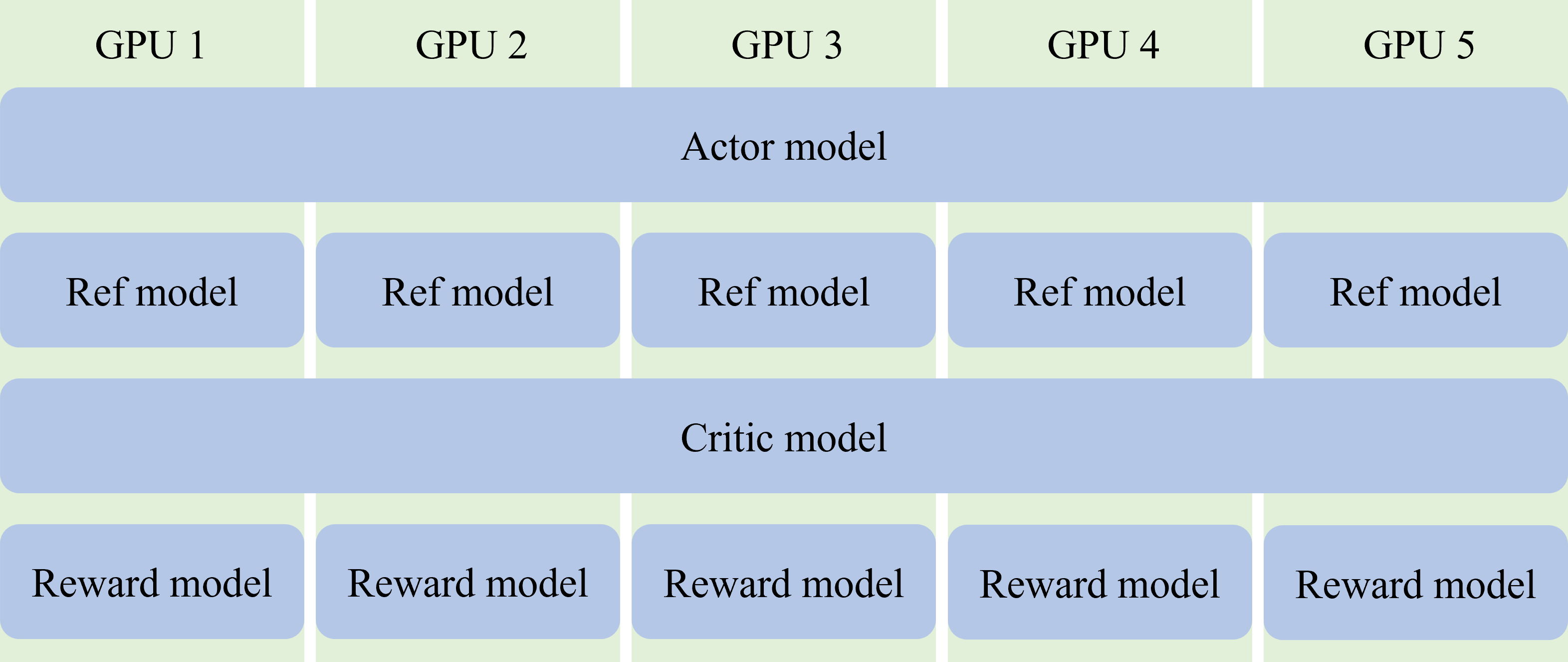
我们将 DeepSpeedChat 这种将所有 model 都分配到相同的 GPU 资源上的结构称为 collocate all models。而在理想的情况下,各个 model 在 GPU 资源上的结构应该如图 4 所示,称为 distribute all models (这是我自己瞎起的😎)。首先,将 actor model 复制为 $2$ 份,一份用于 train,使用 TrainEngine (如 DeepSpeed, FSDP, Megatron) 进行优化,称为 $\pi_{train}$;而另一份用于 rollout,使用 InferEngine (如 vllm, sglang) 进行优化,称为 $\pi_{rollout}$,并在每次 PPO 训练阶段完成后,下一次 PPO 生成阶段开始前,将更新后的 $\pi_{train}$ 的参数同步给 $\pi_{rollout}$。这样做的目的是可以更好地利用目前开源的各个 train/infer engine,提升各个阶段的效率。其次,将每个 model 分配到不同的 GPU 资源上,使其独占给定的 GPU 资源,这样,图 1 中那些没有数据依赖关系的计算模块就可以并行,从而节省整体的时间开销。

题外话 :要使得没有数据依赖关系的计算模块可以并行除了需要将 model 分配到不同 GPU 资源上,另一个关键是要实现每个计算模块的异步调用,而不是像 DeepSpeedChat 那样前一个计算模块完成后才会启动下一个计算模块;同时将每个 model 分配到不同的 GPU 资源上可以避免在一个 GPU 上开太多的进程导致神秘 bug 的等一系列新的问题🥲。
在将每个 model 都分配到不同的 GPU 资源之后,RLHF 的整个流程就可以引入计算模块并行推理,形成如图 5 所示的逻辑流程。可以看到,大多数的计算模块都可以并行进行,与图 1 相比,其可以节省大量的时间开销。下面要讲的 OpenRLHF 和 verl 框架都是使用这种并行的逻辑流程来编写代码的,当然其也包括 collocate all models 的逻辑流程编写的代码。

题外话:虽然上面说了那么多 distribute all models 的好处,但是理论上,在不考虑通信的情况下,collocate all models 才是最优解。在给定 GPU 资源的情况下 (假设给定的 GPU 算力为 $N$),首先,由图 5 可知,每个 model 的计算模块不是每时每刻都可以并行 (如 actor model (rollout) 在 rollout 时,其余 model 只能等待),这必然会导致 GPU 资源的浪费,因此 distribute all models 架构所利用的 GPU 算力的上限 $<N$;而 collocate all models 架构将每个 model 都分布在所有的 GPU 资源上,无论是哪个 model 的计算模块在执行都可以利用所有的 GPU 算力,因此其所利用的 GPU 算力的上限为 $N$,即 collocate all models 所能利用的 GPU 资源上限高。其次,假设 distribute all models 给 $M$ ($M < N$) 个 model 均分 GPU 资源,那么每个 model 所能得到的最大的 GPU 显存为 $M * 单个 GPU 显存$;而 collocate all models 通过 offload 技术,可以实现每个 model 所能得到的最大的 GPU 显存为 $N * 单个 GPU 显存$,因此 collocate all models 加载 model 的上限高。综上所述,collocate all models 架构理论上不仅更快,而且还能训练更大的 model。
因此,collocate all models 架构在 GPU 资源较少的情况下会比 distribute all models 架构更快,HybridFlow 论文中的实验也证明了这一点。这也是为什么 OpenRLHF 和 verl 都实现了 collocate all models 架构的主要原因,而 distribute all models 架构发挥作用的场景在 GPU 资源较多的情况下。举个极端的例子,假设你有 $5$ 台 $8$ 卡 A$100$ 准备训练 $1.5$B 的 model,这时候如果将 $1.5$B model 使用 Megatron/FSDP 等单模型分布式框架分布到 $5 * 8$ 张卡上,由于机间通信等问题,导致大部分时间都在传数据,而不是计算,其时间不一定会比使用 $1$ 台 $8$ 卡 A$100$ 进行训练要短。此时使用 distribute all models 架构,将 5 个 model 各自分配在 $1$ 台 $8$ 卡 A$100$ 上,每个 model 基本上只在机内通信,大大降低了通信时间,增加了计算效率。因此,distribute all models 架构属于是追求极致时间性能的最优解,即给定如下任务:训练一个 $xx$B 的 model,给你无限的卡,只要求训练时间尽可能短。这时候使用 distribute all models 架构比 collocate all models 架构好。图 题外话-1 是我猜测的两个架构随着给定 GPU 资源增加的情况下的训练时间的变化。所以对于我这种“穷人家的孩子”,没有什么计算资源,还是老老实实用 collocate all models 架构才是最佳的选择😅。

与 DeepSpeedChat 一开始就使用 deepspeed 命令启动分布式,并在每个子进程中运行 main.py 不同。关于图 5 所示的逻辑流程的代码编写,由于其需要模块并行,即每个 model 的分布式进程组执行的模块不同 (例如 actor model 的分布式进程组在生成 action logits 时,ref model 的分布式进程组在同时生成 sft logits),因此最直观,也是最具扩展性的方式是使用一个主进程来编写 PPO 的整体计算逻辑 (这个主进程也被称为 single controller),在遇到分布式初始化/计算时,则异步启动/调用各个 model 的分布式进程组,然后继续主进程的下一步计算逻辑,并在之后需要原先分布式进程组结果的时候获取它。因此,整体的代码训练框架如图 6 所示 (由于篇幅限制,这里只展示一小部分代码逻辑)。
题外话:原本的 OpenRLHF 的代码不是 single controller 的模式,而是将 PPO 的计算逻辑分散到各个 model 的分布式进程组中,导致其较难扩展。不过好在现在已经重构为 single controller 的模式了。(有空可以补充 OpenRLHF 旧版本的 multi controller 的代码讲解🤔)
那么如何异步地启动/调用不同 model 的分布式进程组呢?目前 OpenRLHF 和 verl 都采用了 ray 来实现这一目的。ray 有些类似于计算集群管理和调度的软件,通过 ray start 或者 ray.init() 来启动 ray,并指定集群所拥有的 CPU 数,GPU 数等计算资源。接着使用装饰符 @ray.remote() 将某个函数/类装饰为一个 Task/Actor (可以初略地理解为任务),则在后续调用该任务时,ray 会自动将其异步地调度到目前可用的计算资源上,从而减轻我们编写异步代码的难度。
由于 OpenRLHF 和 verl 都是基于 ray 来构建,同时构建逻辑遵循图 5,因此其代码结构有些相似。但是不同的是 OpenRLHF 的分布式进程组的后端使用的是 DeepSpeed 和 vllm;而 verl 的分布式进程组的后端使用的是 FSDP/Megatron 和 vllm/sglang。同时,OpenRLHF 使用 PPORayActorGroup 封装每个 model 的分布式进程组;接着通过统一的 async_run_method_batch() 来调用每个 model 的统一接口 execute_batch(method_name, ...),根据提供的 method_name 的不同来调用不同 model 的具体方法。而 verl 则是使用 WorkerDict 封装所有 model 的分布式进程,并使用 _bind_workers_method_to_parent() 将所有 model 的特有方法 (含有 MAGIC_ATTR 属性的方法)绑定到 WorkerDict 自身上,并进一步使用 RayWorkerGroup() 封装 WorkerDict 的分布式进程组,并使用 _bind_worker_method() 将绑定到 WorkerDict 上的方法进一步绑定到 RayWorkerGroup() 上,从而通过直接调用 RayWorkerGroup() 自身的方法来调用不同 model 的具体方法。
OpenRLHF
接下来,我们讲解 OpenRLHF 的每个模块的逻辑和代码细节:(下面讲解的 OpenRLHF 的版本为 494850f50342ed38d5ae76ef45a3207f3523b582)
如图 7 所示 (这里直接盗用 OpenRLHF 的图片🥳),OpenRLHF 的每个模块的逻辑细节和图 5 类似。在启动时,通过 ray job submit 的方式向 ray 提交运行主进程的 train_ppo_ray.py 文件。在后续的代码分析中,我们先聚焦于每个 model 各自分配不同的 GPU 资源,即 distribute all models 的实现,后面有空再讲解 collocate all models 的实现。关于 OpenRLHF 代码的完整流程图可以查看 Appendix B。train_ppo_ray.py 包括 $3$ 个阶段。第一阶段:首先,实例化 strategy,其是一个 DeepspeedStrategy 类,主要用于构建 model 的 DeepSpeed 分布式进程组,model 的 backward 和参数更新等一系列与分布式初始化/计算以及通信操作有关的内容。接着是构建 vllm 封装的 actor model 用于 rollout,以及构建 PPORayActorGroup 封装的 actor model (用于 train 和 infer),ref model (用于 infer),critic model (用于 train 和 infer),和 reward model (用于 infer)。以 actor model 为例,PPORayActorGroup 的初始化主要涉及初始化 actor model 的分布式进程组的预处理。先是使用 ray 为分布式进程组预分配 GPU 等计算资源,接着初始化 master actor,得到 master actor 的 master addr 和 master port 后,基于此继续初始化剩下的 work actor。以 master actor 的初始化为例,主要是初始化 world size,rank,master addr,master port 等环境变量,为后面真正的 model 的分布式进程组初始化做准备。
第二阶段:首先是初始化 PPOTrainer,它是 PPO 训练和生成阶段的主要类,其初始化主要包括通过 get_tokenizer() 初始化 tokenizer,将之前初始化的各个 model 的分布式进程组赋值给自身的变量,以及 SamplesGenerator 的初始化 (用于使用 vllm 封装的 actor model 进行 rollout),RemoteExperienceMaker 的初始化 (用于 PPO 的生成阶段),通过 prepare_datasets() 构建数据集,以及其他参数/日志的初始化等。接着是 actor model,ref model,critic model 和 reward model 的分布式进程组的初始化。以 actor model 为例,其主要是调用每个分布式进程的 init_model_from_pretrained() 方法。在该方法中,首先调用 strategy 的 setup_distributed() 来初始化分布式进程组的通信后端和分布式进程组的 device mesh;接着初始化 Actor 类,其主要是通过 AutoModelForCausalLM.from_pretrained() 加载指定的 hf model;然后初始化 tokenizer,优化器,学习率 scheduler,并通过 strategy 的 prepare() 方法将 model,优化器和学习率 scheduler 使用 deepspeed 后端进行封装;最后是构建 ActorPPOTrainer 用于 actor model 的 train。其他 model 的初始化过程与 actor model 的初始化过程类似。至此,PPO 的所有初始化便结束了。
第三阶段:这一阶段主要是使用 PPOTrainer 的 fit() 方法执行 PPO 的生成和训练阶段。在该方法中,首先是加载 checkpoint (这里的 checkpoint 指的是整个训练环境,包括 model,dataloader 等的 checkpoint state)。接着开始 args.num_episodes 次 epoch 的训练。对于每一次训练,首先是使用 SamplesGenerator 的 generate_samples() 生成 response,其主要是调用 _generate_vllm() 方法,将给定的 prompt 均匀分配给每一个 vllm 包装的 actor model,并通过 vllm 的 add_requests() 和 get_responses() 来请求和返回生成的 response,最后将其整理并使用 Experience 类进行存放。得到 response 后,接着便使用 RemoteExperienceMaker 的 make_experience_batch() 方法执行 PPO 的生成阶段的剩下部分,包括将 response 组成 batch,调用 make_experience() 方法生成 $p_{RL}$,$p_{SFT}$,$v$,$r$ 以及计算 $KL$,最后调用 compute_advantages_and_returns() 方法生成 $A$ 和 return。如前所述,make_experience() 和 compute_advantages_and_returns() 这两个方法是通过调用各个 model 的分布式进程组的统一的 async_run_method_batch() 接口,并传入具体需要调用的 model 方法的名字来实现的。在 make_experience() 方法中,首先是调用 reward model 的 forward() 方法生成 reward $r$,然后是调用 actor model 的 forward() 方法获取 action logits $p_{RL}$,接着是调用 critic model 的 forward() 方法获取 value $v$,调用 ref model 的 forward() 方法获取 sft logits $p_{SFT}$,最后利用 compute_approx_kl() 方法 (其中包括 k1,k2,k3 三种方式近似计算 $KL$) 计算 KL divergence $KL$。在 compute_advantages_and_returns() 方法中,首先是对 reward $r$ 的后处理 (主要是 PPO 外的其他 RL 算法需要),接着是使用 compute_reward() 方法将 $KL$ 融入到 reward $r$ 中,然后是使用 get_advantages_and_returns() 方法计算 advantage $A$ 和 return,最后对 $A$ 进行归一化处理。而 get_advantages_and_returns() 方法里的内容和 DeepSpeedChat 类似,是使用标准的 GAE 计算 advantage $A$ 和 return 的过程。
在使用 RemoteExperienceMaker 的 make_experience_batch() 方法完成 PPO 的生成阶段后,接下来便是 PPO 的训练阶段。首先是调用 actor model 的 append() 方法和 critic model 的 append() 方法将 PPO 生成阶段的结果存到每个分布式进程的 NaiveReplayBuffer 中,接着便使用 ppo_train() 方法执行 PPO 训练阶段,其内部是调用了 critic model 的 fit() 方法和 actor model 的 fit() 方法分别进行 actor model 和 critic model 的 train,最后将更新的 actor model 参数使用 _broadcast_to_vllm() 方法同步到 vllm 封装的 actor model 中。在 critic model 的 fit() 方法中,主要是调用第二阶段初始化的 CriticPPOTrainer 的 ppo_train() 方法。而 CriticPPOTrainer.ppo_train() 方法内主要包括将 NaiveReplayBuffer 中的 PPO 生成阶段的结果封装为 DataLoader,对于 Dataloader 中的每个 batch,调用 training_step() 方法进行 train (包括生成 new value $V^t$,通过 critic_loss_fn() 来计算 critic loss,调用 strategy 的 backward() 方法和 optimizer_step() 方法进行 backward 和 critic model 的参数更新)。在 actor model 的 fit() 方法中,主要是调用第二阶段初始化的 ActorPPOTrainer 的 ppo_train() 方法。而 ppo_train() 方法内主要包括将 NaiveReplayBuffer 中的 PPO 生成阶段的结果封装为 DataLoader,对于 Dataloader 中的每个 batch,调用 training_step() 方法进行 train (包括生成 new action logits $p^t_{RL}$,通过 actor_loss_fn() 来计算 actor loss 和可选的其他辅助 loss,调用 strategy 的 backward() 方法和 optimizer_step() 方法进行 backward 和 actor model 的参数更新)。在 _broadcast_to_vllm() 方法中,主要是调用 actor model 分布式进程组的 broadcast_to_vllm() 方法,进而调用 ActorPPOTrainer 的 broadcast_to_vllm() 方法 (这个方法细节见 Appendix A) 来实现两个 actor model 之间的参数同步。
总结:如图 8 所示,OpenRLHF 的 distribute all models 使用 PPORayActorGroup 作为所有 model 的分布式进程组的统一类 (除了 actor model (rollout)),且每个 model 各自初始化一个分布式进程组。其中不同 model 的分布式进程使用不同的类进行封装:actor model 使用 ActorModelRayActor 进行封装;ref model 使用 ReferenceModelRayActor 进行封装;critic model 使用 CriticModelRayActor 进行封装;reward model 使用 RewardModelRayActor 进行封装 (每个类的内部本质上都是通过 DeepspeedStrategy 类进行 DeepSpeedEngine 的封装)。而 actor model (rollout) 使用 LLMRayActor 作为分布式进程组的类进行封装,其内部本质是使用 vllm.LLM 来借助 vllm 进行 model 的分布式进程组初始化。最后通过 ray 将所有 model 放置在各自不同的 GPU 资源上,同时按照 PPO 逻辑顺序编写代码实现 single controller 的代码模式。

至此,OpenRLHF 的逻辑和代码细节便已讲解完毕。可以发现,通过 ray 来编写整个代码框架非常的便捷,除了前述的资源管理和分配的优势外,在编写代码时只需要在需要调用 model 的分布式进程组的方法时执行 func_handler=function.remote() 得到执行结果的句柄 (注意,此时函数真正的结果可能还没执行完毕),接着在需要得到执行结果时使用 ray.get(func_handler) 获得结果,即可实现异步的程序执行。同时,由于执行时只获得句柄,如果需要不同 model 的分布式进程组数据转移的逻辑编写,也只需要将在主进程执行 model_1 的 function_1 func_handler=model_1.function_1.remote() 获得句柄,并传递给 model_2 的 function_2 model_2.function_2.remote(func_handler),并在 function_2 里执行 ray.get(func_handler) 即可直接实现由 model_1 向 model_2 传递结果,而不需要主进程作为中介 (主进程只起到一个传递句柄的作用,而不是传递真正的数据)。
verl
最后,我们讲解 verl,由于 verl 实现 distribute all models 的逻辑和代码细节和 OpenRLHF 的非常一致,因此我们先侧重讲解其 collocate all models 的每个模块的代码细节,后面有空再讲解 distribute all models 的代码细节 (其实主要还是因为 verl 目前重点实现了 collocate all models 🫠,下面讲解的 verl 的版本为 78532923368aeb058f62201489546d013df47710)。关于 verl 的 collocate all models 代码的完整流程图可以查看 Appendix C。
相比于 OpenRLHF,verl 的整体架构更加地“工业味”,是一个标准的面向对象开发的 project (即其将所有的东西都视为一个类,包括 model,资源等,同时构造不同的上下文环境管理类来管理不同 model 的上下文)。其 verl/trainer/main_ppo.py 也包括 $3$ 个阶段。第一阶段:首先实例化了一个 TaskRunner 用于作为 single controller,接着构建 model 到 model_class,资源池名称 到 资源数量,model 到 资源池名称 的映射 (Dict 类),然后初始化 reward manager 用于计算 reward,最后初始化训练和测试数据集,以及 sampler 用于训练数据的采样。
第二阶段:其主要是使用 RayPPOTrainer.init_workers() 初始化每个 model 的分布式进程组。首先是使用 create_resource_pool() 创建资源池,并初始化 资源池 到 model_name 和 model_class 的映射 (Dict 类)。接着,使用 create_colocated_worker_cls() 初始化统一的 work_dict_class,其的作用是将每个 model 的方法都统一到一个 class 下,并使用前缀来区分不同 model 的方法 (例如 actor model 的 forward 方法为 actor_forward)。在 create_colocated_worker_cls() 中,首先是使用 _determine_fsdp_megatron_base_class 获取所有 model 的基类,并继承该基类构建新 class WorkDict (即统一的 work_dict_class),WorkDict 的初始化主要包括实例化每个 model,并通过后续的方法绑定将 WorkDict 的方法调用转化为对每个实例化 model 的方法调用。接着是获取每个 model 的 class,并通过 _bing_workers_method_to_parent() 将每个 model 的具有 MAGIC_ATTR 属性的方法绑定到 WorkDict 中,并通过将不同 model 的名称设置为方法的前缀来区分不同 model 的方法。
使用 create_colocated_worker_cls() 生成 WorkDict 后,接下来便是初始化 RayWorkerGroup 生成 wg_dict。在其初始化过程中,首先是使用 _init_with_resource_pool() 初始化 WorkDict 的分布式进程组,其主要包括使用 ray 分配计算资源,获取必要的环境变量,调用 RayClassWithInitArgs.__call__() 初始化分布式进程:对于主进程 (master),其通过 register_center_actor 获取 master_addr 和 master_port;而对于剩下的进程 (worker),其使用 master 获取到的 master_addr 和 master_port。初始化分布式进程后,通过 _bind_worker_method() 方法将 WorkDict 的方法绑定到 RayWorkerGroup 上,这次绑定和 _bing_workers_method_to_parent() 中不同的是其额外获取了 dispatch,execute 和 block 等模式用于定义分配方法的输入,执行方法,以及收集方法的输出的模式。
在初始化 wg_dict 后,接着使用 spawn() 方法将其为每个 model 复制一份,其使用 from_detached() 来实例化 RayWorkerGroup,主要包括使用 _init_with_detached_workers() 复制 wg_dict 中的 WorkDict 实例;将 WorkDict 的方法绑定到 RayWorkerGroup 上;使用 _rebind_actor_methods() 根据 model 的名称来去除 RayWorkerGroup 方法中的前缀并进行重新绑定 (例如这个 RayWorkerGroup 是复制给 actor model 的,则将其中含 actor_* 名称的方法全部恢复为 * 的名称)。在复制完成后,每个 model 的分布式进程组便已初始化完毕,最后便是实例化每个 model。以实例化 actor model 为例,其主要是通过调用 ActorRolloutRefWorker.init_model() 来进一步调用 _build_model_optimizer() 方法实例化 model,optimizer 和 lr scheduler。在 _build_model_optimizer() 中,首先是使用 hf_tokenizer() 实例化 tokenizer,接着通过 AutoConfig.from_pretrained() 和 get_generation_config() 分别获取 model 的 config 和 generate config。然后使用 get_init_weight_context_manager() 初始化上下文环境 (主要是用于指明实例化 model 的位置,CPU or GPU 等),并通过 AutoModelFroCausalLM.From_pretrained() 实例化 model。接着便是初始化混合精度设置,使用 get_fsdp_wrap_policy() 初始化 auto_wrap_policy,初始化分片策略,并通过这些来构建最终的 FSDP model (关于构建 FSDP 的更多细节可以参考我之后的博客),最后初始化 optimizer 和 lr scheduler。在 _build_model_optimizer() 结束后,进一步使用 DataParallelPPOActor 将 model 进行进一步封装,并使用 _build_rollout() 初始化 model (rollout) 用于 rollout,包括使用 init_device_mesh() 初始化 device mesh;使用 vLLMRollout 构建 vllm 封装的 model;以及使用 FSDPVLLMShardingManager 构建 rollout_sharding_manager 作为 model rollout 时的上下文管理器。构建完 actor model (rollout) 后,最后便是通过 FSDPCheckpointManager 构建 checkpoint_manager 来管理 model 的 checkpoint。
第三阶段:该阶段主要是使用 RayPPOTrainer.fit()实现 PPO 的生成和训练阶段。在 PPO 生成阶段,首先是给定被构造为 DataProto 的 prompt 并通过 ActorRolloutRefWorker.generate_sequences() 生成 response。在 generate_sequences() 中,首先是通过 rollout_sharding_manager 上下文管理器获取 actor model 的参数并使用 sync_model_weights() (这个方法细节见 Appendix A) 将其同步给 vllm 封装的 actor model,接着使用 preprocess_data() 收集进程组的所有 prompt,并通过 generate_sequences() 生成 response,最后使用 postprocess_data() 将生成的 response 进行分块,并退出 rollout_sharding_manager 上下文管理器。生成 response 后,接下来是使用 RewardModelWorker.compute_rm_score() 生成 reward $r$,其主要包括通过 ulysses_sharding_manager 上下文管理器设置 sequence parallel;使用 preprocess_data() 收集进程组的所有 rm_data 和 data,并通过 split() 将其划分为 micro batch 大小;使用 _forward_micro_batch() 来调用 reward_module 的 forward() 生成 $r$;最后使用 postprocess_data() 将生成的 response 进行分块,并退出 ulysses_sharding_manager 上下文管理器。生成 reward $r$ 后,使用 ActorRolloutRefWorker.compute_log_prob() 生成 action logtis $p_{RL}$,其主要包括通过 ulysses_sharding_manager 上下文管理器设置 sequence parallel;使用 preprocess_data() 收集进程组的所有 data,并使用 DataParallelPPOActor.compute_log_prob() 生成 $p_{RL}$;最后退出 ulysses_sharding_manager 上下文管理器。接着使用 ActorRolloutRefWorker.compute_ref_log_prob() (其与生成 action logtis $p_{RL}$,即 ActorRolloutRefWorker.compute_log_prob() 相同的步骤) 生成 sft logtis $p_{SFT}$。然后使用 CriticWorker.compute_values() 生成 value $v$,其步骤与生成 action logtis $p_{RL}$ (ActorRolloutRefWorker.compute_log_prob()) 相同,除了将中间的使用 DataParallelPPOActor.compute_log_prob() 生成 $p_{RL}$ 的步骤替换为使用 DataParallelCritic.compute_values() 生成 $v$。最后是使用 apply_kl_penalty() 计算 KL divergence $KL$ 并将其融入到 $r$ 中,并通过 compute_advantage() 生成 advantage $A$ 和 return。至此,PPO 生成阶段便已完成。
在 PPO 训练阶段,其主要是调用 critic model 的 updata_critic() 方法和 actor model 的 update_actor() 来训练两个 model。在 updata_critic() 中,除与之前一致的上下文环境管理外,主要是使用 DataParallelPPOCritic.update_critic() 训练 critic model,其中包括使用 _forward_micro_batch() 生成 new value $v^t$;使用 core_algos.compute_value_loss() 计算 critic loss;最后进行 backward 并使用 DataParallelPPOCritic._optimizer_step() 更新 critic model 参数。而在 update_actor() 中,除与之前一致的上下文环境管理外,主要是使用 DataParallelPPOActor.update_policy() 训练 actor model,其中包括使用 _forward_micro_batch() 生成 new action logits $p^t_{RL}$;使用 core_algos.compute_policy_loss() 计算 actor loss;最后进行 backward 并使用 DataParallelPPOActor._optimizer_step() 更新 actor model 参数。至此,PPO 训练阶段便已完成。
总结:如图 9 所示,verl 的 collocate all models 实现使用 RayWorkerGroup 作为所有 model 的分布式进程组的统一类,且每个 model 各自实例化一个 RayWorkerGroup;但是每个 RayWorkerGroup 的内部真实的分布式进程组 (即 self._workers) 都是指向同一组 WorkDict 列表。而在每个分布式进程,即每个 WorkerDict 中,则是实例化所有 model:actor model 和 ref model 使用 ActorRolloutRefWorker 进行封装;critic model 使用 CriticWorker 进行封装;reward model 使用 RewardModelWorker 进行封装 (每个类的内部本质上都是通过 FSDP/Megatron 类进行封装)。而 actor model (rollout) 和 actor model 一同封装在 ActorRolloutRefWorker 中,使用的是 verl 论文中提出的 3D-HybridEngine 技术 (这个后面有空可以讲一下,其实这是一个 verl 区别于 OpenRLHF 很重要的技术)。由于所有的 model 都使用同一个资源池,因此 ray 会将所有 model 放置在相同的 GPU 资源上。最后按照 PPO 逻辑顺序编写代码使用 TaskRunner 和 RayPPOTrainer 实现 single controller 的代码模式。

至此,verl 的代码细节便已讲解完毕。可以发现,verl 的代码非常擅于利用装饰器和上下文管理器来实现预处理步骤以及逻辑的封装,甚至能够利用 __new__ 的初始化来编写自身的代码 (例如 register_center_actor 的实例化便是在 Worker 类的 __new__ 中)。这种方式的优点是可以实现很强的代码复用,以及很容易进行模块化扩展,但是缺点就是代码的逻辑阅读性可能不是很好。不过感觉公司的项目应该很喜欢这种风格的代码,更符合多人协作的范式,大家还是要多多熟悉 (我也要多多熟悉😉)。
TODO List: 1. Appendix A 的 OpenRLHF 和 verl 的 vllm 与 actor model 的参数同步;2. 3D-HybridEngine 技术 (Appendix D)。</p> 1. 在 Appendix A: Actor Model 与 vllm 的参数同步的实现细节
OpenRLHF 的
敬请期待🤪broadcast_to_vllm()verl 的
敬请期待🤪sync_model_weights()Appendix B: OpenRLHF 代码流程图

train_ppo_ray.py 的代码流程
create_vllm_engines() 的代码流程
PPORayActorGroup() 的代码流程
PPOTrainer() 的代码流程
PPORayActorGroup.async_init_model_from_pretrained() 的代码流程
PPOTrainer.fit() 的预处理和PPO 生成阶段的代码流程
PPOTrainer.fit() 的预处理和PPO 训练阶段的代码流程Appendix C: verl 代码流程图

main_ppo.py 的TaskRunner.run()的代码流程
load_reward_manager() 的代码流程
RayPPOTrainer() 的代码流程
init_workers() 的代码流程
fit() 的代码流程Appendix D: verl 代码额外细节
verl 的
register_center_actor 的实现Worker 的 __new__ 方法中,*_register_center 的实例化需要满足 int(os.environ.get("DISABLE_WORKER_INIT", 0)) == 0,None not in [rank, worker_group_prefix] 和 "ActorClass(" not in cls.__name__,而在 WorkerDict 的 __init__ 中,使用 with patch.dict(os.environ, {"DISABLE_WORKER_INIT": "1"}) 的上下文环境避免实例化各个 model 时生成 *_register_center;而在 remote_cls = ray.remote(WorkerDict) 时,会调用 WorkDict 的 __new__ 方法,此时 "ActorClass(" not in cls.__name__ 条件避免生成 *_register_center;最后在 RayWorkerGroup._init_with_resource_pool() 时,worker = ray_cls_with_init(...) 会调用 self.cls.options(**options).remote(...),这个 self.cls 就是 WorkDict,此时将其实例化会再次调用 Worker 的 __new__,且其的 cls.__name__ 为 WorkDict,没有外套 ActorClass,因此会成功调用 Worker._configure_before_init() 实例化 *_register_center。因此 int(os.environ.get("DISABLE_WORKER_INIT", 0)) == 0,None not in [rank, worker_group_prefix] 和 "ActorClass(" not in cls.__name__ 这三个条件都是为了防止其他位置不合时宜地实例化 *_register_center (感觉应该是在写代码的过程中发现了这些漏洞一个个加上的 (bushi))。(所以我比较疑惑 ray.remote() 封装时调用了类的 __new__ 的作用是什么?🤔)verl 的
敬请期待🤪 ActorRolloutRefWorker 的实现