
Animate Anyone
Published:
论文题目:Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
发表会议:截至2023年12月03日暂无,论文版本为 arxiv-v1
第一作者:Li Hu (Alibaba Group)
Question
如何提高 Character Animation video generation model 生成视频的一致性(consistency),可控性(controllability)以及连续性(continuity)
Preliminary
Character Animation:是视频生成领域的一个子任务。通过给定一个角色的图片(可以是真人,动漫等)以及其他指导信息(如文本(text),姿态(pose)等,称为条件)来生成满足条件的该角色的动态视频。
Method
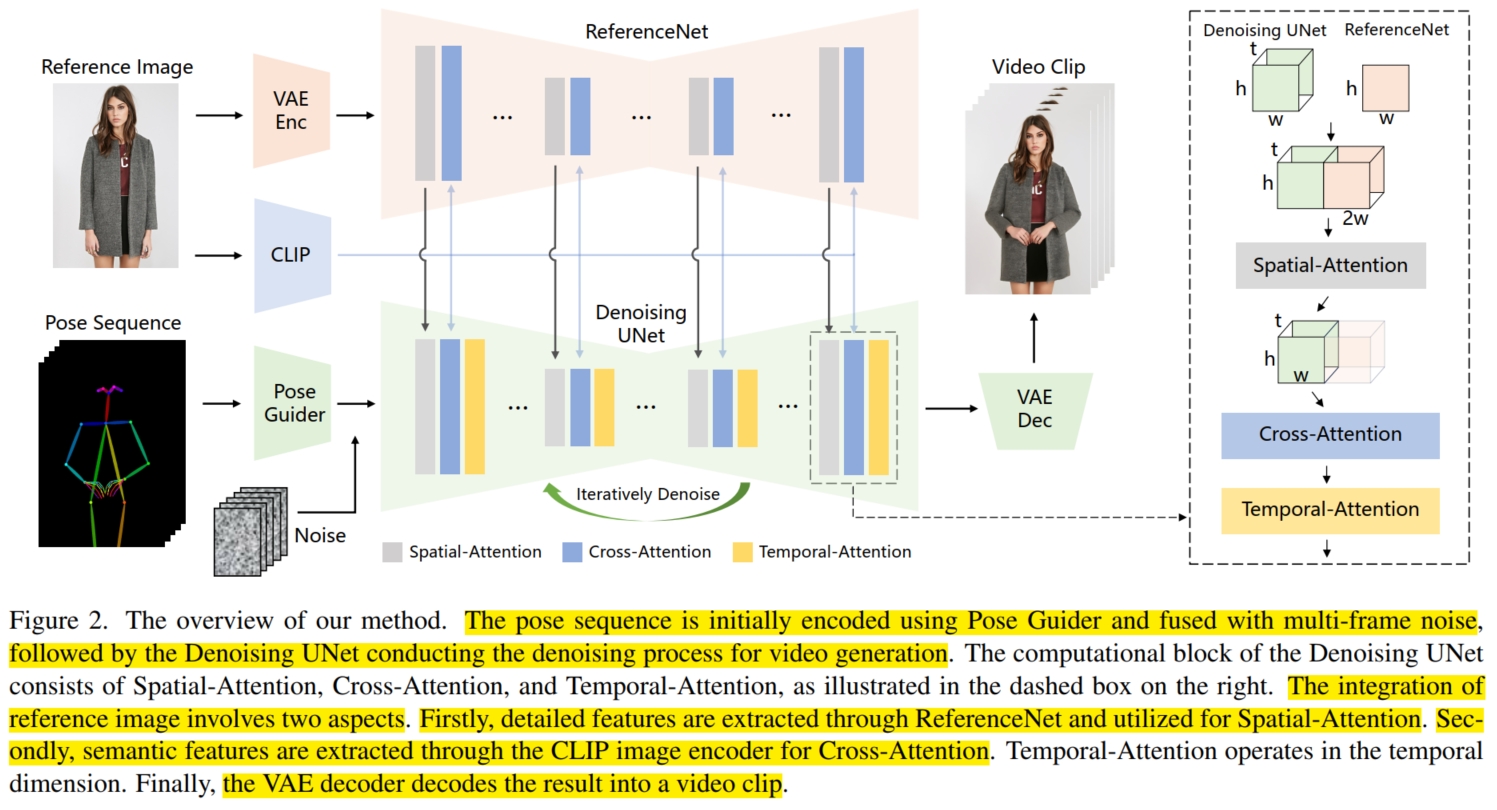
本文主要聚焦于使用 pose 作为指导信息(条件)的 Character Animation 任务。 目前主流的生成方法大都使用 DM 模型,输入高斯分布噪声,输出去噪的图像/视频;而对于条件,通常使用额外的 encoder 将其编码为对应的 embedding,然后使用 cross-attention 融合进 DM 模型的学习中。 这对于 text 等这种高语义的条件来说没什么问题,但是对于 image、pose 等这种低语义的条件来说,仅仅使用 embedding 来约束模型的生成显然不够, 因为 embedding 将原始的细节信息进行压缩(如 image 中的表征信息、pose 的局部细节信息等),导致模型在还原这些细节信息时会导致不一致。 (举个简单的例子,假设输入一个真人图像 $\mathcal{I}$ 和一系列 pose 图像 $\{p_i\}_{1:N}$,要求模型生成该真人图像对应的 pose 的视频 $\{v_i\}_{1:N}$, 将 $\mathcal{I}$ 和 $\{p_i\}_{1:N}$ 编码为 embedding 后,其细节信息便被压缩了(比如 $\mathcal{I}$ 中的胡子的形状轮廓,$\{p_i\}_{1:N}$ 中的每张图像的每根手指的长度等), 很可能导致模型在生成时出现不一致(如第 $i+1$ 帧的胡子比 $i$ 帧的茂密,第 $i+1$ 帧的手指比 $i$ 帧的长等)。)
为此,本文通过将输入条件进行更加精细的编码融合,使得模型能更好地学习条件的细节信息,同时又不损失类似 text 的高语义信息。 具体而言,本文使用 Stable Diffusion 模型(SD)作为 backbone。 假设模型输入给定的角色图像 $\mathcal{I}$ 和 pose 视频帧 $\{p_i\}_{1:N}$,以及初始噪声视频 $\{z_i^T\}_{1:N}$。 在 $\mathcal{I}$ 条件的处理中,首先使用 SD 模型中的 VAE encoder 将 $\mathcal{I}$ 编码为 detail image embedding $\mathcal{I}_d \in \mathbb{R}^{h_d \times w_d \times c_d}$ 作为细节信息的条件; 同时使用 CLIP 的 video embedding 将 $\mathcal{I}$ 编码为 sematic image embedding $\mathcal{I}_s \in \mathbb{R}^{h_s \times w_s \times c_s}$ 作为高语义信息的条件。 然后设计一个 ReferenceNet 来输入 $\mathcal{I}_d$ 构建逐级细节信息,以更好地帮助 SD 模型学习。为了方便融合,ReferenceNet 的架构和 SD 模型一致,都是使用 U-net 模型, SD 模型的每一层主要包括 self-attention 和 cross-attention。在第 $l$ 层,输入 $\mathcal{I}_d^l$ 首先经过 self-attention, 然后与 $\mathcal{I}_s$ 进行 cross-attention 生成 $\mathcal{I}_d^{l+1}$ 作为下一层的输入($\mathcal{I}_d = \mathcal{I}_d^1$)。 最终生成不同分辨率的细节信息 $\mathcal{I}_d^l \in \mathbb{R}^{h_d^l \times w_d^l \times c_d^l}, l=[1,..,L]$。
而在 $\{p_i\}_{1:N}$ 的条件处理中,本文使用 Pose Guider (一个简单的 2D 卷积块)将 $\{p_i\}_{1:N}$ 编码为 pose embedding $\{f_i\}_{1:N} \in \mathbb{R}^{N \times h_d \times w_d \times c_d}$。 注意,$f_i$ 的维度和 $\mathcal{I}_d$ 一致,这样可以方便后续的融合。
对于主体过程(即视频生成),本文使用 SD 模型进行 $T$ 步的逆扩散过程学习。在第 $t$ 步时,首先将第 $t-1$ 步得到的含噪视频 $\{z_i^{\color{red}{t-1}}\}_{1:N}$ 与 $\{f_i\}_{1:N}$ 进行逐元素相加, 即 $\{z_i\}_{1:N} = \{z_i^{\color{red}{t-1}} + f_i\}_{1:N}$ 作为 SD 模型的输入(红色上标表示代表逆扩散过程的步骤 $t$, 绿色上标表示代表 U-net 的层级 $l$)。 在第 $l$ 层,输入 $\{z_i^\color{green}{l}\}_{1:N}$,首先在经过 self-attention 时, 本文将 $\{z_i^\color{green}{l}\}_{1:N}$ 与 $\mathcal{I}_d^l$ 在 $w$ 的维度上进行 concat 以实现 $\mathcal{I}$ 的逐级细节信息的融合, 即首先将 $\mathcal{I}_d^l$ 复制 $N$ 次,然后与 $\{z_i^\color{green}{l}\}_{1:N}$ 在 $w$ 维度上 concat 形成 $2*w_d^l$ 的维度长度:$\{\hat{z}_i^\color{green}{l}\}_{1:N} = concat(\{z_i^\color{green}{l}\}_{1:N}, copy(\mathcal{I}_d^l, N)) \in \mathbb{R}^{N \times h_d^l \times 2*w_d^l \times c_d^l}$。 然后将 $\{\hat{z}_i^\color{green}{l}\}_{1:N}$ 输入到 self-attention 进行学习,且对于 self-attention 的输出在 $w$ 维度上仅取前 $w_d^l$ channel (输出中一个有 $2*w_d^l$ channel), 获得输出 $\{\bar{z}_i^\color{green}{l}\}_{1:N} \in \mathbb{R}^{N \times h_d^l \times w_d^l \times c_d^l}$ (由于与普通的 self-attention 不同,本文称该层为 spatial-attention)。 接着与 $\mathcal{I}_s$ 进行 cross-attention 生成 $\{\tilde{z}_i^\color{green}{l}\}_{1:N} \in \mathbb{R}^{N \times h_d^l \times w_d^l \times c_d^l}$。 由于 SD 模型是图像生成模型,而本文需要生成视频,因此还需要学习视频帧之间的一致性。为此,本文在 cross-attention 之后添加了一个 temporal-attention 层, 促进模型在 $N \times c$ 维度上的学习,最终输出 $\{z_i^{\color{green}{l+1}}\}_{1:N}$ 作为下一层的输入。
最终经过 $T$ 次去噪过程后,生成的无噪 $\{z_i^\color{red}{0}\}_{1:N}$ 使用 SD 模型中的 VAE decoder 将其还原为原始视频帧 $\{v_i\}_{1:N}$。
在训练阶段,本文采用两阶段的训练方式。第一阶段,使用单视频帧训练模型:首先使用预训练的 SD 模型初始化本文的 SD 模型和 ReferenceNet, Pose Guider 使用高斯分布初始化(最后一层使用 zero convolution 初始化),同时训练时 VAE 和 CLIP image encoder 的权重保持不变(即不参与训练)。 然后在视频片段中随机选择一张作为给定的角色图像 $\mathcal{I}$,并随机选择另一张 $v_r$ 及其对应的 pose 视频帧 $p_r$ 作为训练图像。 在这一阶段没有训练 temporal-attention 层,即将 SD 模型作为标准的图像生成模型进行训练,$\mathcal{I}$ 和 $p_r$ 的融合方式和上述一致(只是 $\mathcal{I}_d^l$ 无需复制 $N$ 次)。 而在第二阶段,引入 temporal-attention 层并使用 AnimateDiff 进行初始化,同时使用视频片段进行训练,且只训练 temporal-attention 层(固定其他模块参数权重)。